Как сделать робота на ROS своими руками. Часть 3: распознавание речи для голосового управления
Привет всем любителям робототехники!
Мы продолжаем совершенствовать нашего робота под кодовым именем «Abot», построенного на инфраструктуре операционной системы ROS. На каждом этапе мы расширяем функциональные возможности робота и рассказываем, с какими проблемами столкнулись и как их решили.
Данная статья полностью посвящена работе со звуком. В этот раз мы на конкретных примерах расскажем вам:
- Как добавить роботу слух. Мы запустим на роботе систему автоматического распознавания человеческой речи в реальном времени.
- Как добавить роботу голос. Мы встроим в робота систему синтеза человеческой речи и голосовой движок.
- Как реализовать голосовое управление роботом. Сперва мы рассмотрим простые голосовые команды, а затем интегрируем голосовое управление в систему навигации.
Эта статья — продолжение цикла про систему ROS. Мы не будем разбирать здесь основы работы с ROS, а продолжим работу над сделанным ранее роботом. Рекомендуем вам ознакомиться с предыдущими статьями:
Как и раньше, наш робот работает на Raspberry Pi 4 Model B под управлением Ubuntu 20.04.2.0 Server arm64 и ROS Noetic.
Данная статья может оказаться полезной даже тем, кто не увлекается роботами и не следит за нашим проектом. Описанные нами примеры работы с человеческой речью могут пригодиться в других ваших проектах, например, в голосовых ассистентах. Кроме этого, для повторения большинства примеров даже не понадобится робот — достаточно лишь компьютера или одноплатника Raspberry Pi.
Исходный код проекта нашего робота, а также конструкторские САПР-файлы и исходники можно найти в репозитории Abot на GitHub.
Содержание
- Звуковые устройства
- Распознавание речи
- Пример приложения «Speech-to-Text»
- Синтез речи
- Голосовое управление роботом
- Заключение
Звуковые устройства
Для работы со звуком роботу понадобятся дополнительные устройства ввода-вывода: микрофон, чтобы слышать, и динамик, чтобы воспроизводить звук.
Это важно! Если вы захотите повторить данный проект, ваши звуковые устройства, скорее всего, будут отличаться от тех, что используем мы. Эта статья не является обязательной пошаговой инструкцией, а описывает конкретный пример. В действительности вы никак не ограничены в выборе звукового железа. Главное, чтобы выбранные вами звуковые устройства правильно определились и заработали в операционной системе Linux.
Звуковая карта
Выводить звук на Raspberry Pi 4 Model B можно только через HDMI-порт, либо через 3,5-миллиметровый разъём TRS (mini-jack) на плате. Микрофона на плате Raspberry и вовсе нет, как и какого-либо встроенного интерфейса для работы с внешними микрофонами.
Помимо ограниченных возможностей вывода ещё и качество звука на RPi оставляет желать лучшего. Всё дело в том, что Raspberry генерирует не аналоговый звуковой сигнал через цифро-аналоговый преобразователь (DAC), а псевдо-аналоговый, используя аппаратный ШИМ-сигнал. Поэтому сгенерированный звук получается «грязным», с помехами и шипением, а также тихим из-за отсутствия выходного усилителя.
На Raspberry Pi 4 всего два канала с поддержкой ШИМ: PWM0 и PWM1. И оба они заняты, поскольку мы используем их для управления моторами робота. Поэтому мы даже не можем использовать мини-джек для вывода звука с платы Raspberry. Нам нужно дополнительное оборудование — звуковая карта.
На рынке существует множество звуковых карт в виде модулей для Raspberry Pi. Наверное, самими популярными являются звуковые платы Subtronics и HiFiBerry. Практически все подобные платы расширения общаются с процессором Broadcom на RPi по аппаратному интерфейсу I²C. Чтобы такие модули правильно определились в системе Linux как звуковые устройства, нужно вмешательство в ядро ОС. Производители плат пишут специальные установочные скрипты, однако все они рассчитаны на установку в среде официальной системы Raspberry Pi OS. Мы же используем стороннюю ОС Ubuntu, и для нас собирать драйвера для подобных звуковых плат будет крайне проблематично.
Идеальным решением в нашем случае является использование внешней USB-звуковой карты, которая позволяет подключить практически любой микрофон и любой динамик. А с USB-интерфейсом нам не понадобятся никакие дополнительные драйверы звука в Linux.
Разновидностей внешних звуковых карт с USB очень много. Цена звуковой карты, как правило, пропорциональна её качеству и может варьироваться от двухсот до десятков тысяч рублей. Внешние звуковые карты очень распространены, и вы наверняка сможете найти их в ближайшем магазине компьютерной техники.
В этом проекте мы воспользовались внешней звуковой картой Creative Sound Blaster Play 3, у которой два мини-джека: вход для микрофона и линейный выход.

Динамики и усилитель звука
Для вывода звука к аудиокарте можно подключить, например, маленькую портативную USB-колонку на пару ватт. Однако мы решили сделать вывод звука своими руками, используя два динамика и стереоусилитель.
Для начала мы взяли простой усилитель класса D в формате одноюнитового Troyka-модуля.

Данный усилитель питается от 5 В и потребляет до 1 А. Питание для усилителя мы можем взять с порта USB 3.0 на Raspberry Pi. Troyka-усилитель — двухканальный, максимальная выходная мощность звука — 1,5 Вт на один канал при нагрузке 8 Ом.
В тандем к усилителю мы взяли два динамика VECO 32KC08-1. У них пластиковый диффузор, сопротивление 8 Ом и максимальная мощность 3 Вт. Модель динамика подбиралась исходя из запаса по мощности.

Подключаем динамики к клеммникам Troyka-усилителя акустическими проводами, по одному динамику на канал. Сам усилитель подключаем к линейному выходу звуковой карты через TRS-штекер с клеммниками.
Для устранения фоновых шумов на «холостом ходу» припаяем пару керамических конденсаторов на 0,1 мФ в разрыв правого и левого канала на выходе из звуковой карты. Конденсаторы изолируем термоусадкой.

Для подвода питания к Troyka-усилителю мы обрезали ненужный кабель USB.

Вот так выглядят наши колонки в сборе вместе со звуковой картой:

Микрофон
При наличии внешней звуковой карты можно использовать практически любой микрофон, например компьютерный или микрофон от гарнитуры с наушниками.
Однако не стоит пренебрегать качеством микрофона! Чем лучше микрофон и записанный на нём звук, тем легче будет нашему программному обеспечению с этим звуком работать.
Для нас важнейшим фактором при выборе микрофона является его направленность. Крайне желательно использовать всенаправленный микрофон.
В конечном итоге этот микрофон будет установлен на роботе, который ездит по полу. Следовательно, микрофон должен «улавливать» наши голосовые команды, поступающие со всех сторон и с достаточного большого расстояния. Мы хотим общаться с роботом, словно с человеком, чтобы не приходилось подходить к нему вплотную и кричать на него в надежде, что он нас услышит. Всенаправленный микрофон справится с такой задачей гораздо лучше, чем однонаправленный или двунаправленный.
Идеальным решением было бы использование массива из нескольких отдельных микрофонов, расположенных по кругу, как это сделано, например, в умных колонках типа «Яндекс.Станции» и Amazon Alexa. Сделать такой массив своми руками технически очень сложно — потребуется уникальная печатная плата, прошивка и куча электронных компонентов. Хотя у компании SeeedStudio существуют готовые решения, например массив микрофонов с управлем по USB — ReSpeaker USB Mic Array или массив микрофонов в виде платы расширения для Raspberry Pi — ReSpeaker 4-Mic Array for Raspberry Pi.
В этом проекте мы воспользовались небольшим настольным микрофоном для компьютерных конференций Audio-Technica ATR4697, который рассчитан на всенаправленное улавливание звука.

Данный микрофон бывает в двух исполнениях: с подключением через USB или через 3,5-миллиметровый разъём TRS. Нам досталась версия с USB-подключением.
При наличии звуковой карты всё же лучше найти микрофон с мини-джеком 3,5 мм и сэкономить таким образом один USB-порт на управляющей плате.
Подключение к Raspberry Pi
Подключим всё наше звуковое оборудование к роботу. Для этого нам в сумме понадобятся три USB-порта Raspberry Pi: один для звуковой карты, один для микрофона и один для питания усилителя.
Наша схема подключения выглядит так:
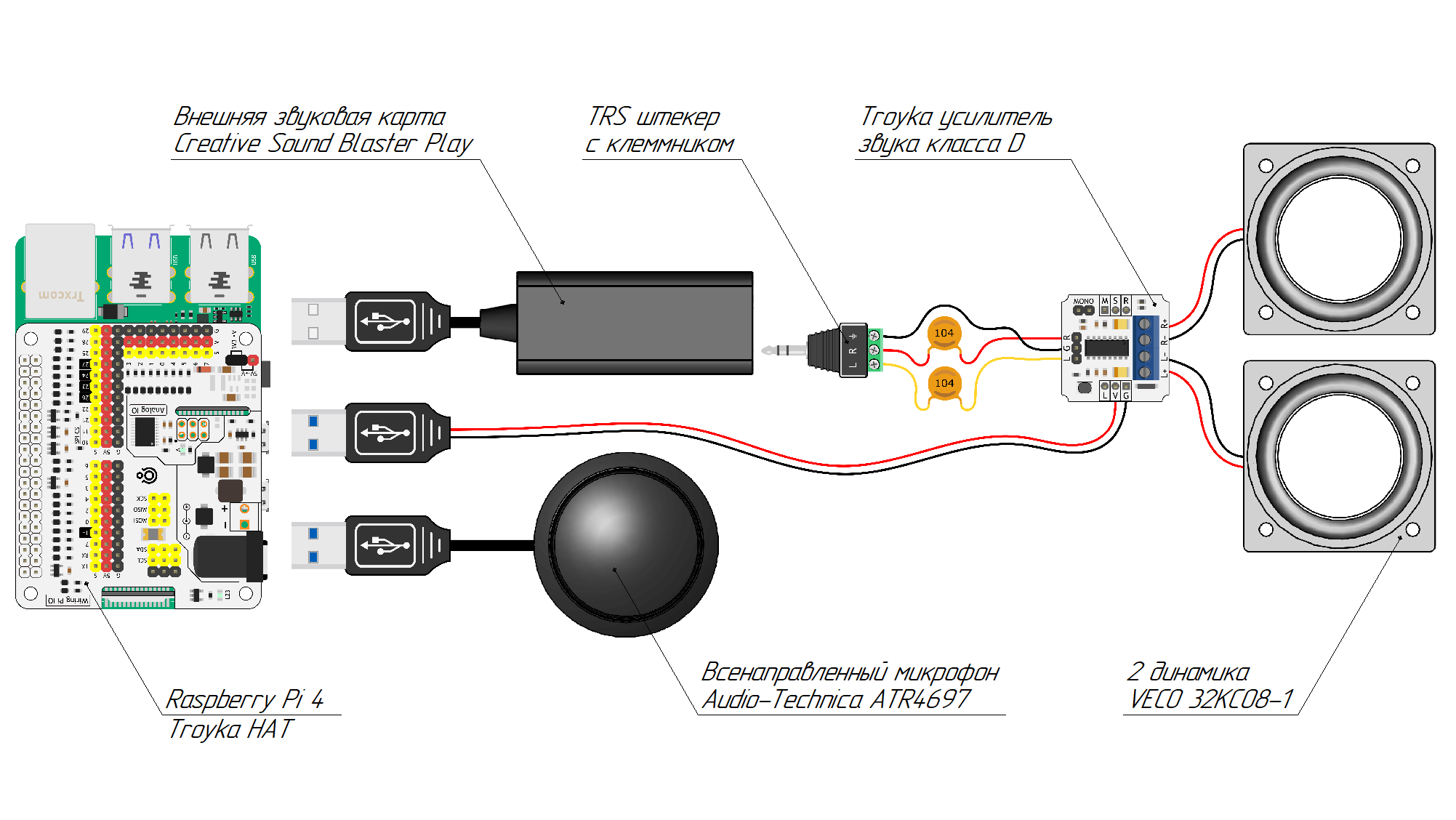
Пока что для тестирования и отладки мы подключим всё это дело к роботу без какого-либо крепления:

Проверка звука в Linux
Протестируем, как работают наши звуковые устройства.
Для нас важно, чтобы драйверы для всех наших устройств были доступны в звуковой подсистеме Linux — ALSA. Посмотреть глобально все имеющиеся в системе звуковые устройства (или карты, cards) можно командой:
cat /proc/asound/cards
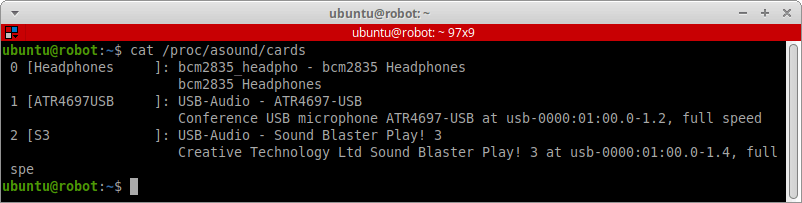
У нас в системе определелись три устройства. Каждое из них имеет свой уникальный индекс. Например, в нашем случае:
0— родной разъём мини-джек для наушников на плате Raspberry Pi.1— USB-микрофон.2— внешняя USB-звуковая карта.
Посмотреть все устройства в системе, способные захватывать звук, можно командой:
arecord -l
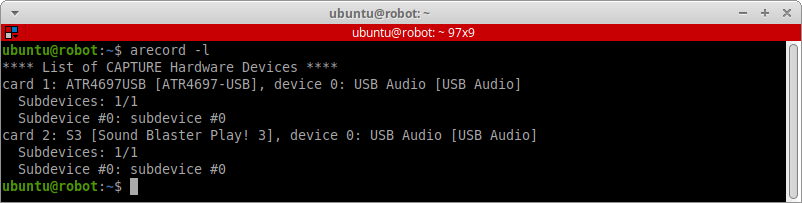
Нам доступен ввод звука через:
- Устройство с индексом
1— USB-микрофон. - Устройство с индексом
2— микрофонный вход на внешней USB-звуковой карте.
Посмотреть все устройства для воспроизведения звука в системе можно командой:
aplay -l
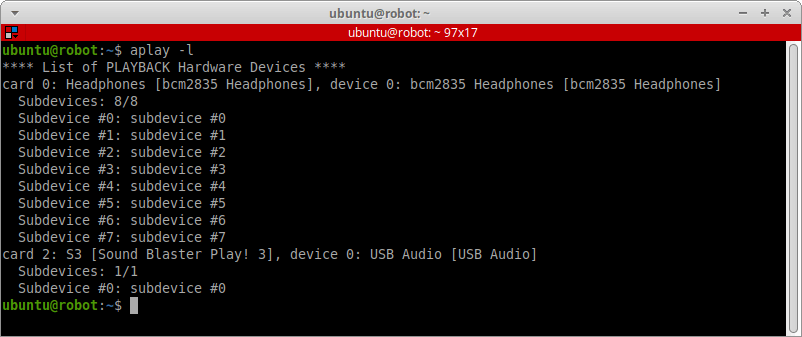
Нам доступен вывод звука через:
- Устройство с индексом
0— разъём мини-джек для наушников на плате Raspberry Pi. - Устройство с индексом
2— линейный выход на внешней USB-звуковой карте.
Попробуем записать пробный звук, сохранить его в файл, а затем воспроизвести.
Немного теории. Физически звук представляет собой колебание волн в окружающей среде. Как и любая волна, звук характеризуется амплитудой и частотой и описывается аналоговым сигналом или функцией. В компьютере же вся информация хранится в цифровом виде. Простейшим методом оцифровки звука является использование aналого-цифрового преобразователя (АЦП или ADC) и импульсно-кодовой модуляции (ИКМ или PCM). Оцифрованный таким образом звук представляется в виде последовательности цифровых семплов (sample) — мгновенных значений уровня аналогового сигнала, измеряемого АЦП через равные промежутки времени. Звук в виде цифровых семплов уже можно сохранить на компьютере.
Сейчас и далее мы будем хранить цифровой звук в несжатом виде в контейнерах типа WAV или иногда Ogg.
Записываем звук той же командой arecord со следующими параметрами:
arecord -f S16_LE -d 10 -r 16000 -c 1 -D plughw:1 /tmp/test-mic.wav
Указанные значения параметров для нас очень важны, так как именно эти значения будут в дальнейшем использоваться при работе с человеческой речью. Лучше сразу протестировать запись звука с нужными значениями:
-f S16_LE— формат записи, глубина или разрядность квантования при импульсно-кодовой модуляции. Мы используем форматS16_LE(Signed 16-bit c порядком байтов little-endian). На каждый семпл звука будет приходиться два байта, и каждый семпл будет оцифрован числом в диапазоне [-32768, 32768]. Считается, что погрешности квантования звука с разрядностью 16 бит остаются для человека почти незаметными.-c 1— количество каналов записи. Мы записываем монофонический звук (моно), поэтому указываем1канал.-d 10— длительность записи в секундах. Для теста запишем фрагмент на 10 секунд.-r 16000— частота дискретизации (sample rate) при импульсно-кодовой модуляции. Измеряется в герцах. Ставим значение 16000 Гц. Это значит, что при кодировании аналогового звука семплы будут создаваться 16000 раз в секунду.-D plughw:1— крайне важный параметр. Здесь мы указываем индекс звукового устройства в системе Linux, которое нужно использовать для захвата звука. Индекс устройства можно задать обращениемplughw:1или простоhw:1. При обращенииhw:1осуществляется прямой доступ к звуковому устройству. Но более безопасно использовать обращение типаplughw:1, при котором система ALSA будет сама использовать плагины преобразования сигналов при появлении несостыковок, например, в частоте дискретизации или формате записи. Мы записываем звук на USB-микрофон. В нашей системе он имеет индекс устройства1./tmp/test-mic.wav— сохраняем нашу запись в файл WAV во временной папке.

Кстати, зная параметры записи, мы можем легко посчитать, сколько памяти она в итоге будет занимать. 16 бит разрядности × 16000 Гц частоты × 1 канал × 10 секунд записи = 2560000 бит или 320000 байт или 312,5 килобайт.
Теперь воспроизведём сохранённый WAV-файл командой aplay:
aplay -D plughw:2 /tmp/test-mic.wav
В параметрах указываем:
-D plughw:2— индекс звукового устройства в системе Linux, которое нужно использовать для воспроизведения звука. Мы собираемся проигрывать звук через наши самодельные колонки, подключённые к внешней USB-звуковой карте с индексом2./tmp/test-mic.wav— указываем путь до WAV-файла, который хотим воспроизвести.

Если всё было настроено верно, вы должны услышать записанный вами аудиофайл.
Командой alsamixer можно установить громкость воспроизведения и громкость записи звука, если это поддерживается вашим микрофоном.
alsamixer
Переключаться между громкостью различных звуковых карт можно клавишей F6. Установим выходную громкость примерно на 70% от максимального значения, чтобы наши колонки не хрипели и не надрывались.

Из всего множества библиотек для работы со звуком мы будем использовать мультимедийный фреймворк GStreamer. Этот фреймворк обязательно нам понадобится, так как далее в проекте мы будем использовать основанные на нём ROS-пакеты.
Обычно GStreamer уже предустановлен в системе Ubuntu. Если вдруг фреймворка нет, вы можете провести его полную установку командой:
sudo apt-get install libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgstreamer-plugins-bad1.0-dev gstreamer1.0-plugins-base gstreamer1.0-plugins-good gstreamer1.0-plugins-bad gstreamer1.0-plugins-ugly gstreamer1.0-libav gstreamer1.0-doc gstreamer1.0-tools gstreamer1.0-x gstreamer1.0-alsa gstreamer1.0-gl gstreamer1.0-gtk3 gstreamer1.0-qt5 gstreamer1.0-pulseaudio
Протестируем микрофон и динамики, используя GStreamer. Например, попробуем непрерывно захватывать звук с микрофона и сразу же воспроизводить его через наши динамики.
Для этого воспользуемся командой gst-launch-1.0, в которой укажем следующий «pipeline»: alsasrc → audioconvert → audioresample → alsasink с указанием индексов звуковых устройств:
gst-launch-1.0 alsasrc device=plughw:1 ! audioconvert ! audioresample ! alsasink device=plughw:2
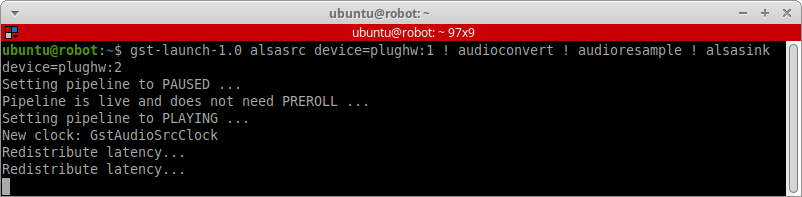
Немного отодвинем микрофон от колонок, чтобы он не слышал сам себя, не шумел и не провоцировал гудящую обратную связь. Уменьшим громкость на колонках и микрофоне процентов до 70% и протестим потоковый звук.
Если вы слышите в колонках то, что вы говорите в микрофон — значит ваш звук настроен, и можно двигаться дальше.
Изменение индексов аудиоустройств
У вас может возникнуть проблема при использовании множества USB-аудиоустройств.
По умолчанию в операционной системе индексирование звуковых устройств происходит не всегда одинаково.
Например, у вас два звуковых устройства: USB-микрофон и USB-динамик. Они подключаются к Raspberry Pi и оба правильно определяются в Linux как звуковые карты (cards). Микрофону присваивается индекс 1, а динамику индекс 2. Затем вы перезагружаете Raspberry Pi или просто переподключаете USB-устройства. И вот уже динамик получает индекс 1, а микрофон — 2. Вроде бы ничего страшного, но если у вас есть готовая программа, работающая с аудио, то вам придется править её исходный код и менять индексы звуковых устройств.
Такая же проблема возникла и у нас, и вот как можно её решить.
Смотрим список звуковых карт в системе:
cat /proc/asound/cards
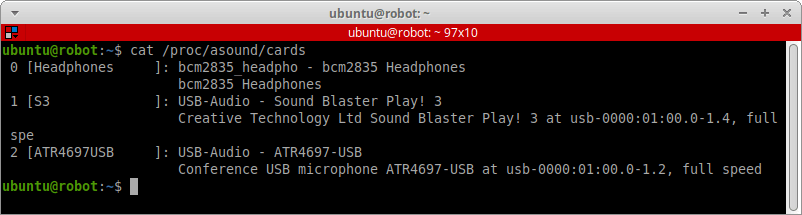
Видим, что USB-микрофон имеет индекс 2, а внешняя USB-звуковая карта индекс 1. Мы же хотим, чтобы было c точностью наоборот: микрофон под номером 1, звуковая карта под номером 2, и чтобы так было всегда.
Смотрим список всех подключённых USB-устройств:
lsusb
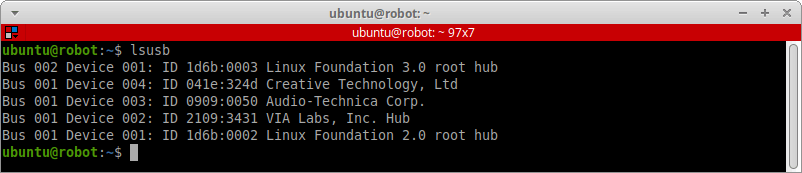
Здесь нам нужно посмотреть и запомнить уникальные идентификаторы USB-устройств. Они указаны через двоеточие как VendorID:ProductID. Например, наш USB-микрофон Audio-Technica Corp. имеет ID производителя 0909 и ID продукта 0050. USB-звуковая карта Creative Technology, Ltd имеет ID производителя 041e и ID продукта 324d.
Открываем файл конфигурации модулей Linux для подсистемы ALSA:
sudo nano /etc/modprobe.d/alsa-base.conf
И добавляем в конец файла следующие строчки:
options snd_bcm2835 index=0
options snd_usb_audio index=1,2 vid=0x0909,0x041e pid=0x0050,0x324d
options snd slots=snd_bcm2835,snd_usb_audio
Этими строчками мы вручную переопределяем порядок индексирования звуковых модулей. Сперва мы задаём встроенному на Raspberry Pi звуковому модулю snd_bcm2835 индекс 0. Теперь устройство вывода звука на разъём для наушников всегда будет иметь индекс 0.
Затем мы задаём индексы для модуля snd_usb_audio, который отвечает за USB-звуковые устройства в системе. Наши USB-устройства получили индексы 1 и 2 — index=1,2. Причём индекс 1 получило USB-устройство с VendorID 0x0909 и ProductID 0x041e (наш микрофон), а индекс 2 — устройство с VendorID 0x041e и ProductID 0x324d (внешняя звуковая карта) — vid=0x0909,0x041e pid=0x0050,0x324d. Здесь все идентификаторы указываются в шестнадцатеричном формате, так что перед идентификатором нужно поставить префикс 0x.
Финальной строчкой задаём порядок индексирования модулей: options snd slots=snd_bcm2835,snd_usb_audio.
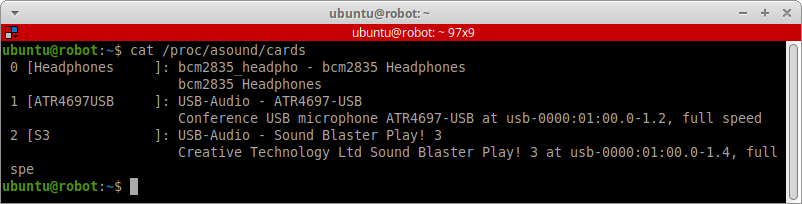
Перезагружаем Raspberry Pi и смотрим на обновлённые индексы звуковых карт.
sudo reboot now
cat /proc/asound/cards
Распознавание речи
Распознавание речи (Speech recognition) — это огромная область компьютерных наук и компьютерной лингвистики, которая разрабатывает методы и технологии, позволяющие распознавать разговорную речь и переводить её в цифровую информацию, например в текст.
Подобный процесс также часто называют «автоматическим распознаванием речи», или сокращённо ASR (Automatic Speech Recognition). Технологию преобразования речи в текст часто называют просто «Speech-to-Text», или сокращённо STT.
Весь процесс распознавания речи сложен для понимания обычным неподготовленным человеком. В конце концов, мы собираемся использовать готовое программное обеспечение, и нам не обязательно становиться профи в этой области науки. Однако нам всё же придётся разобраться в основах распознавания речи, чтобы понять общий принцип работы нашей программы.
История технологии
Системы распознавания речи появились очень давно. Их развитие происходило поэтапно: при открытии революционно новых компьютерных технологий системы распозавания речи делали резкий скачок вперёд. Ключевые области развития — объём словарного запаса, независимость системы от диктора и скорость обработки информации.
Первая система по преобразованию речи «Audrey» от компании Bell Laboratories появилась в 1952 году и служила только для распознавания цифр. Данное изобретение распознавало речь только специально обученного диктора. В качестве свойств звукового сигнала использовались спектральные резонансы в гласных в каждой цифре.
В конце 50‑х годов XX века был создан модуль, способный распознать уже десять гласных вне зависимости от диктора. А в 60-х годах была создана первая система, которая распознавала фонемы.
В 70-е годы произошли два серьезных открытия. Первое — это алгоритм динамической трансформации временной шкалы, или DTW-алгоритм (Dynamic time warping), основанный на временном выравнивании речевых диалектов. Второе — метод кодирования линейного предсказания, или LPC-метод (Linear Predictive Coding), основанный на анализе и оценке формант гласных и прочих расширенных частотных полос в звуках человеческой речи. Этот метод был очень эффективно использован при качественном распознавании речевых сигналов с низким битрейтом.
В середине 80-х годов системы распознавания речи перешли к использованию принципиально другого метода — статистического моделирования с использованием скрытой модели Маркова, или HMM (Hidden Markov Models).
С конца 80-х годов системы распознавания речи начали строиться на нейронных сетях (Artificial Neural Network). Рост вычислительной мощности компьютеров позволил создавать всё более сложные нейросети и использовать для их обучения больший объём звуковых данных.
С развитием интернета и мобильных технологий большинство систем «Speech-to-Text» перешли на облачные вычисления. Подобные передовые системы используют сложную комбинацию из всех вышеописанных методов. Сочетание нескольких моделей в одной системе позволяет более качественно распознавать речь.
Классификация систем распознавания речи
На сегодняшний момент выделяют несколько признаков, по которым классифицируются процессы преобразования человеческой речи в цифровую информацию.
По размеру словаря:
- малый словарь — порядка 100 слов;
- средний словарь — порядка 1000 слов;
- большой словарь — порядка 5000 и более.
При большом словаре велика вероятность получения ошибок при распознавании. Если словарь состоит из десяти цифр, которые между собой не созвучны, то такой словарь будет распознан практически без ошибок. А если выбрать словарь из нескольких тысяч слов, вероятность ошибки существенно возрастает. Если в словаре присутствует очень много омофонов, точность распознавания может уменьшится практически до нуля.
По зависимости от диктора:
- дикторозависимые;
- дикторонезависимые.
Дикторозависимая система предназначена для использования одним человеком, поэтому её можно точно настроить под параметры конкретного диктора. В таких системах частота ошибок в разы ниже по сравнению с дикторонезависимыми системами — алгоритм сводится к обучению системы распознавания на основе одного голоса.
Дикторонезависимая система сложнее, так как должна приспосабливаться к особенностям произношения разных людей, их темпу и тембру речи, ритму и такту. Такие системы разработаны для использования абсолютно разными людьми.
По типу речи:
- слитная речь;
- связные слова и фразы;
- отдельные слова.
Обычно слова в нашей речи разделены между собой небольшим участком тишины. Если эта тишина присутствует, то такая речь — раздельная. В противном случае речь слитная. Наша повседневная речь как раз слитная, и распознавать её программно гораздо сложнее, так как слова не имеют чётких границ, а звуки на стыке двух слов могут «смазываться».
По качеству распознаваемой речи:
- чистая речь;
- слабо зашумлённая речь;
- сильно зашумлённая речь.
Под чистой речью понимается звуковой сигнал, содержащий только речь без каких-либо помех. На практике же невозможно сделать идеально чистую аудиозапись. На фоне записанной человеческой речи постоянно будут посторонние шумы или голоса других людей. Существуют разные алгоритмы подавления шума, однако распознать зашумлённую речь очень сложно.
По типу структурной единицы:
- по фонемам;
- по частям слов;
- по словам.
Речь человека формируется произношением отдельных звуков, при объединении которых образуются осмысленные слова и предложения. При создании системы распознавания речи можно выделить неделимые элементарные единицы: фонемы, слоги, слова, или же задать их искусственно. Качество распознавания неоднозначно зависит от выбора тех или иных единиц, поэтому они определяются требованиями к конкретной системе.
Архитектура систем распознавания речи
Процесс распознавания речи в общем виде можно разложить на несколько этапов:
- Извлечение акустических признаков из входного звукового сигнала.
- Акустическое моделирование.
- Языковое моделирование.
- Декодирование.
Извлечение акустичесих признаков проходит разными методами. Наиболее популярный метод — мел-частотные кепстральные коэффициенты, или MFCC (Mel-Frequency Cepstrum Coeffcents). Данный метод основан на особенностях человеческого слуха и представлении сигнала в мел-шкале. Другой метод — анализ перцептивного линейного предсказания, или PLP (Perceptual Linear Predictive), который связан с неравной восприимчивостью слуха на разных звуковых частотах. Методов много, они могут использоваться как по одному, так и в комбинациях.
Акустическая модель — это функция, которая принимает на вход акустические признаки на небольшом участке аудиосигнала (фрейме) и выдаёт распределение вероятностей различных фонем на этом фрейме. Таким образом, акустическая модель даёт возможность по звуку восстановить, что было произнесено — с той или иной степенью уверенности. Самой популярной реализацией акустической модели является скрытая Марковская модель (HMM), в которой скрытыми состояниями являются фонемы, а наблюдениями — распределения вероятностей признаков на фрейме.
Языковая модель позволяет узнать, какие последовательности слов в языке более вероятны, а какие менее. Язык обычно моделируется с помощью статистических языковых моделей — SLM (Statistical Language Models) или конечно определённых регулярных грамматик — FSG (Finite State Grammar). В самом простом случае от статистической языковой модели требуется предсказать следующее слово по известным предыдущим словам. Традиционно применяются модели типа N-грамм, в которых на основе большого количества текстов оценивается распределение вероятности появления слова в зависимости от N предшествующих слов. Для получения надёжных оценок распределений параметр N должен быть достаточно мал: одно, два или три слова — модели униграмм, биграмм или триграмм соответственно.
Задача автоматического распознавания речи сводится к определению наиболее вероятной последовательности слов, соответствующих содержанию речевого сигнала. Наиболее вероятный кандидат должен определяться с учётом как акустической, так и лингвистической информации. Это означает, что необходим эффективный поиск среди возможных кандидатов с учётом различной вероятностной информации. При распознавании слитной речи число таких кандидатов огромно, и даже использование самых простых моделей приводит к серьёзным проблемам, связанным с быстродействием и памятью систем. Как результат, эта задача выносится в отдельный модуль системы автоматического распознавания речи, называемый декодером.
Выбор системы распознавания речи
Выберем программное обеспечение для распознавания речи на нашем роботе.
Готовых систем распознавания речи очень много, они основаны на разных методах, обладают разной производительностью и заточены под разные устройства.
Определимся, какие критерии систем «Speech-to-Text» нас интересуют в первую очередь:
- Язык. Мы говорим на русском языке и хотим, чтобы наш робот мог распознать повседневную русскую речь.
- Дикторонезависимость. Роботом может управлять любой человек.
- Точность распознавания. Нам не нужно, чтобы робот идеально распознавал всю нашу речь и слово в слово выдавал нам точные субтитры. С другой стороны, робот должен различать слитную повседневную речь и с минимальным количеством ошибок выделять из неё небольшое количество заданных нами голосовых команд.
- Требуемая вычислительная мощность. Программное обеспечение должно быть легковесным, ведь мы собираемся использовать его на Raspberry Pi, а не на мощном стационарном компьютере.
- Цена. Хотелось бы, чтобы распознавание голоса было для нас бесплатным, или ограничилось бы небольшим разовым платежом.
Прежде всего на ум приходят облачные системы «Speech-to-Text». Каждый уважающий себя IT-гигант имеет своё решение:
- Yandex.SpeechKit
- Amazon Transcribe
- Google Speech-to-Text
- IBM Watson Speech to Text
- Microsoft Azure Speech
Принцип работы облачных сервисов прост. Отправляете на сервер запрос, содержащий аудиофрагмент записанной речи, и получаете ответ — распознанный в этом фрагменте текст. Облачные системы поддерживают множество языков, в том числе и русский. Точность распознавания речи в таких системах очень высокая. Вычислительная мощность не требуется, ведь все вычисления происходят на серверной стороне.
Однако у всех подобных систем есть два существенных минуса. Первый — это необходимость в постоянном интернет-подключении. Но робот может работать где-нибудь на улице без Wi-Fi и мобильного интернета. Кроме этого хочется, чтобы робот был независим от различного рода условий и мог полноценно работать в оффлайне.
Второй минус — это цена. Все облачные системы платные, причём цена сервиса зависит от количества распознанных в речи символов. Робот должен непрерывно слушать человеческую речь, чтобы в реальном времени обнаружить момент, когда обращаются именно к нему. Например, в течение двух часов мы можем дать роботу всего пару голосовых команд длиной в несколько десятков символов, и эти распознанные символы будут для нас результативными. В остальное же время мы будем просто болтать о своих делах, но робот продолжит нас слушать, распознавать всё, что мы говорим, и ждать команды. За пару часов мы можем наговорить тысячи нерезультативных для нас символов, и за них всё равно придётся заплатить. Поэтому облачные системы «Speech-to-Text» нам не подходят.
Популярные оффлайн-системы распознавания речи:
Мы выбрали облегчённую версию системы CMU Sphinx — PocketSphinx.
Данная система не может похвастаться высокой точностью. В сравнении с другими решениями у PocketSphinx наибольший процент ошибок при распознавании — WER (Word Error Rate).
С другой стороны, система PocketSphinx, на наш взгляд, самая документированная и популярная среди новичков. PocketSphinx очень легко настроить. Система обладает наименьшим показателем отношения времени распознавания к длительности распознаваемого сигнала, также известного как SF (Speed Factor). Как следствие, данная система быстрее работает на слабых компьютерах типа Raspberry Pi.
В PocketSphinx при извлечении признаков из аудиосигнала используются методы MFCC и PLP. Акустическое моделирование реализовано через HMM, языковое моделирование — SLM или FSG, среди которых есть русскоязычные модели.
Движок PocketSphinx написан на С, но существуют обёртки и для других языков, например для Python.
Установка PocketSphinx
Устанавливаем PocketSphinx на Raspberry Pi.
Перед установкой PocketSphinx на Raspberry Pi нужно убедиться, что у вас установлены gcc, automake, autoconf, libtool, bison, swig и ещё пара утилит для теста:
sudo apt-get install bison swig
sudo apt-get install alsa-utils libasound2-dev
Для работы PocketSphinx нужно установить две библиотеки — sphinxbase и pocketsphinx.
Для Ubuntu 20.04.2.0 Server, которую мы используем, есть готовый пакет для arm64 последней версии 0.8.0+real5prealpha с библиотеками libpocketsphinx3 и libsphinxbase3.
sudo apt-get install pocketsphinx
В идеале после его установки больше ничего делать не нужно. Однако для других систем, возможно, придётся выполнить компиляцию и установку библиотек вручную. Как это сделать, вы можете узнать в Wiki-документации или на GitHub проекта CMU Sphinx.
Мы будем работать с PocketSphinx на Python, и для этого установим специальный пакет-обёртку.
sudo apt-get install python3-pocketsphinx
Проверить правильность установки PocketSphinx без конкретной программы, модели и настроек довольно сложно. Но можно протестировать встроенное приложение pocketsphinx_continuous из терминала с английским языком.
Скачайте тестовую акустическую модель:
sudo apt-get install pocketsphinx-en-us
Отключите все звуковые устройства от Raspberry Pi, кроме микрофона, запустите тестовое приложение и попробуйте сказать в микрофон «Hello World».
pocketsphinx_continuous -inmic yes -keyphrase "hello world" -kws_threshold 1e-50
Стек пакетов для работы с аудио в ROS
Мы собираемся работать со звуком и аудиофайлами. В ROS для этого нам нужен специальный пакет. Всё, что нам потребуется, есть в стандартном стеке пакетов audio_common.
Просто устанавливаем его в нашу систему ROS Noetic:
sudo apt-get install ros-noetic-audio-common
Данный стек пакетов является ROS-интерфейсом к фреймворку GStreamer, который мы установили ранее. Перечислим пакеты стека:
audio_capture— пакет для ввода аудио, например с микрофона или из файла.audio_play— пакет для вывода аудио, например через динамики или в файл.sound_play— пакет для связи топиков ROS со звуками и аудиофайлами. Также данный пакет содержит простой синтезатор речиfestival.audio_common_msgs— пакет, определяющий тип сообщений для обмена аудиоданными внутри ROS.
Пакет abot_speech_to_text
В нашем рабочем пространстве ROS создадим метапакет (наш собственный стек пакетов) и назовём его abot_sound. Он будет содержать все ROS-пакеты нашего робота «Abot», которые каким-либо образом связаны со звуком. При этом пакеты внутри стека будут тесно взаимодействовать между собой.
В стеке abot_sound создадим первый пакет и назовём его abot_speech_to_text. Этот пакет будет отвечать за распознавание речи в ROS на нашем роботе, а также в нём будут храниться различные настройки наших STT-систем.
В пакете abot_speech_to_text создадим четыре папки: config для различных настроек, launch для файлов запуска, scripts для файлов с исходным кодом на Python и model для акустических моделей PocketSphinx.
При создании новых пакетов в ROS не забываем оформлять файлы CMakeLists.txt и package.xml. В качестве пакетов зависимостей для abot_speech_to_text устанавливаем пакеты:
Также в файле package.xml укажем, что для исполнения Python-скриптов в этом пакете нам понадобится сторонний от ROS пакет pocketsphinx:
<exec_depend>python3-pocketsphinx</exec_depend>
В папке launch пакета abot_speech_to_text создадим пока что пустой файл запуска abot_speech_to_text.launch. Этим файлом мы будем запускать все наши ноды для распознавания речи.
Собираем проект:
catkin_make
Запуск записи звука
Прежде чем разбирать речь, необходимо её записать. Нам нужно организовать потоковую запись звука c микрофона и трансляцию записанного аудио в топик ROS. Для этого воспользуемся готовой нодой audio_capture из пакета audio_capture.
В файле abot_speech_to_text.launch запустим ноду audio_capture со следующими параметрами:
<launch>
<!-- Audio capture params -->
<arg name="device" default="plughw:1"/>
<arg name="bitrate" default="160"/>
<arg name="channels" default="1"/>
<arg name="sample_rate" default="16000"/>
<arg name="sample_format" default="S16LE"/>
<arg name="dst" default="appsink"/>
<arg name="format" default="wave"/>
<node name="audio_capture" pkg="audio_capture" type="audio_capture" output="screen">
<param name="bitrate" value="$(arg bitrate)"/>
<param name="device" value="$(arg device)"/>
<param name="channels" value="$(arg channels)"/>
<param name="sample_rate" value="$(arg sample_rate)"/>
<param name="sample_format" value="$(arg sample_format)"/>
<param name="format" value="$(arg format)"/>
<param name="dst" value="$(arg dst)"/>
</node>
</launch>
В качестве параметров звукозаписи мы указываем те же самые параметры, которые использовали при тесте звуковых устройств в Linux. Одноканальное 16-битное аудио формата WAV с частотой 16000 Гц и битрейтом 160 бит/с.
Обязательно указываем, какое звуковое устройство device нужно использовать для записи. Мы используем наш USB-микрофон с индексом 1 в системе — plughw:1.
Запускаем потоковую запись. Перед этим не забываем о запуске ядра ROS roscore в отдельном терминале на Raspberry Pi или на любой другой машине в сети ROS.
source devel/setup.bash
roslaunch abot_speech_to_text abot_speech_to_text.launch
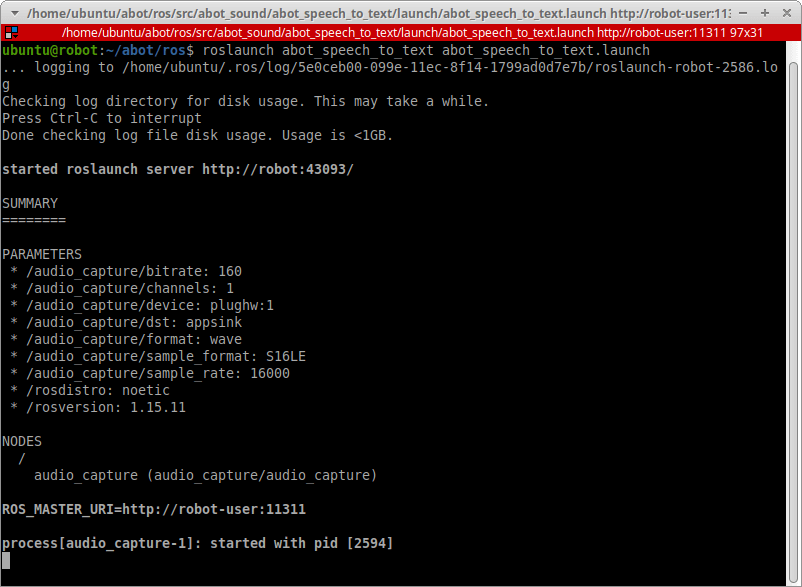
В новом терминале взглянем, какие топики у нас появились:
rostopic list

Аудиоданные с микрофона поступают в топик /audio, а в топике /audio_info содержится информация о параметрах аудиозаписи.
Посмотрим, что находится в топике /audio:
rostopic echo /audio
В топик /audio поступают сообщения типа AudioData, которые, по сути, представляют собой массив «сырых» байтов звука с микрофона:

Посмотрим, с какой частотой приходят сообщения:
rostopic hz /audio

Сообщения приходят порционно — раз в 10 мс, то есть с частотой 100 Гц. При такой частоте каждое аудиосообщение содержит 320 байт, что соответствует 160 семплам при 16-битном формате аудиозаписи.
Звук с микрофона поступает в нашу систему ROS, а значит, мы можем двигаться дальше.
Пример приложения «Speech-to-Text»
Разберём процесс распознавания речи и настройки движка PocketSphinx на простом и конкретном примере.
Допустим, наш робот умеет только включать-выключать два светодиода — красный и зелёный — и управлять их яркостью.
Для примера создадим программу голосового управления этими светодиодами.
Ключевые фразы
Начнём настройку PocketSphinx с самого простого режима, который называется «Поиск по ключевым словам», или Keyword Spotting.
В режиме Keyword Spotting мы указываем точное ключевое слово, фразу (keyphrase) или даже список слов и фраз, которые хотим распознавать в речи. Все эти ключевые слова и фразы помещаются в специальный файл (kwslist) и «скармливаются» движку.
Принцип работы прост: на вход программы поступают аудиоданные, движок непрерывно анализирует абсолютно всю речь, которая в них содержится. Если какое-то слово (или фраза) из речи вероятностно похожа на то, что хранится в (kwslist), то оно выдаётся на выход программы.
Режим поиска по ключевым словам хорош для точного выявления в слитной речи отдельных слов или сочетаний двух-трёх слов. Но мы хотим, чтобы наш робот принимал голосовые команды в виде сложных и составных предложений. Режим Keyword Spotting для этого не очень подходит, нужна специальная грамматика.
Однако у этого режима есть интересная особенность, которой мы воспользуемся. Мы можем использовать Keyword Spotting для того, чтобы робот определял, что человек обращается именно к нему.
Это похоже на ситуацию из реальной жизни, когда человека зовут по имени. Представьте, например, что вас зовут Саша и вы занимаетесь какими-то своими делами в болтающей толпе окружающих вас друзей. Вы хорошо слышите всё, что говорят люди вокруг, но не вслушиваетесь в их беседу и не анализируете её — сейчас вам нет до этого дела. Но если кто-то вдруг позовёт вас по имени, например «Эй, Саша!», ваше внимание сразу же концентрируется — вы ждёте следующие слова от того, кто обратился к вам, и уже не пропустите их мимо ушей.
Так будет и с нашим роботом. Программа с режимом Keyword Spotting будет быстро анализировать всю речь вокруг и концентрироваться на поиске опредлённого ключевого слова или фразы. Если такое слово будет найдено, то вся последующая речь будет подвергнута более тщательному анализу.
На самом деле вы хорошо знакомы с режимом Keyword Spotting. Вот пример ключевой фразы или слова:
- «Алиса!» у Яндекса.
- «Сири!» у Apple.
- «Окей, гугл!» у Google.
- «Эй, Джарвис!» у Тони Старка.
Ключевые слова и фразы должны быть не слишком длинные, но и не короткие. Чем больше в ключевой фразе слов, или чем больше у ключевого слова слогов, тем меньше вероятность ложного обнаружения. PocketSphinx рекомендует использовать ключевые слова как минимум с тремя-четырьмя слогами.
Пусть ключевым словом для нашего Abot’а будет просто «Робот».
Теперь нужно создать файл, в котором будут храниться все ключевые слова или фразы. Это нужно сделать, даже если ключевое слово у нас только одно. В PocketSphinx данный файл имеет расширение .kwslist.
В папке config пакета abot_speech_to_text создадим папку test, а в ней файл test_kwslist.kwslist.
В этот файл нужно построчно внести все ключевые слова и фразы со специальным числовым пороговым значением (threshold) в диапазоне от 1e-50 до 1e-1. Пороговые значения пишутся сразу за ключевыми словами и фразами со следующим синтаксисом: /1e-40/.
Пороговые значения нужны для задания точности выделения ключевых слов в непрерывной речи. Для более коротких ключевых фраз используются большие пороговые значения, для более длинных ключевых фраз порог должен быть меньше.
Если ваша ключевая фраза очень длинная (более 10 слогов), рекомендуется разделить её на отдельные ключевые части. Пороговое значение нужно выбрать таким образом, чтобы обеспечить баланс между ложными срабатываниями анализатора и пропущенными обнаружениями в речи.
Наше ключевое слово «Робот» очень короткое, всего два слога. Вероятность ложного определения такого слова в речи очень велика, так что мы поставим низкое пороговое значение — 1e-5.
В итоге наш список test_kwslist.kwslist имеет одну строку и выглядит следующим образом:
робот /1e-5/
В идеале пороговые значения для ключевых слов и фраз подстраиваются уже на рабочем приложении PocketSphinx, а последовательность настройки выглядит так:
- Выбираете ключевое слово и указываете для него произвольное пороговое значение.
- Записываете аудио длиной, например, 1 час с различными диалогами, в которых присутствует ваше ключевое слово. При этом вы точно знаете, сколько раз ваше слово встречается на аудиозаписи.
- Запускаете метод распознавания Keyword Spotting на вашей аудиозаписи и считаете, сколько раз алгоритм найдёт ваше ключевое слово.
- Если алгорим обнаружил в записи больше слов, чем их было на самом деле — значит порог нужно увеличить. Если алгоритм нашел меньше ключевых слов — значит порог нужно уменьшить.
Голосовые команды
Придумаем голосовые команды для робота. Команды должны следовать непосредственно за ключевым словом или фразой. Вот голосовые команды, которые мы придумали для этого примера.
Наш робот может включить и выключить зелёный светодиод:
- «Робот, включи зеленый светодиод».
- «Робот, выключи зеленый светодиод».
Может включить и выключить красный светодиод:
- «Робот включи красный светодиод».
- «Робот выключи красный светодиод».
Может включить и выключить все светодиоды:
- «Робот, включи все светодиоды».
- «Робот, выключи все светодиоды».
Может управлять яркостью отдельного светодоида от 0 до 100% с шагом в 10%.
- «Робот, установи яркость красного светодиода ноль/десять/двадцать/тридцать/сорок/пятьдесят/шестьдесят/семьдесят/восемьдесят/девяносто/сто».
- «Робот, установи яркость зеленого светодиода ноль/десять/двадцать/тридцать/сорок/пятьдесят/шестьдесят/семьдесят/восемьдесят/девяносто/сто».
Всего получилось 28 возможных вариантов команд.
Акустическая модель
Теперь нам нужна акустическая модель для используемого языка.
Языковых моделей очень много, все они подготовлены для различных акустических условий и разных требований по производительности. Список всех предлагаемых CMU Sphinx моделей языка можно посмотреть на SourceForge. Файлы языковых моделей имеют большой объём.
Для русского языка мы скачиваем модель в архиве zero_ru_cont_8k_v3.tar.gz. Его нужно разархивировать и переместить папку zero_ru_cont_8k_v3 в папку model нашего пакета abot_speech_to_text.
cd ros/src/abot_sound/abot_speech_to_text/model
curl -L https://downloads.sourceforge.net/project/cmusphinx/Acoustic%20and%20Language%20Models/Russian/zero_ru_cont_8k_v3.tar.gz > zero_ru_cont_8k_v3.tar.gz
tar -xf zero_ru_cont_8k_v3.tar.gz
Фонетический словарь
Следющий шаг — определить, какие слова вообще должен распознавать наш робот. Для этого нам нужно сформировать фонетический словарь — файл, в котором лексемы (слова) сопоставлены последовательности фонемов (транскрипция) акустической модели языка.
Из всех наших команд нужно выделить все уникальные слова. Итого у нас получилось 24 уникальных слова: «робот», «включи», «выключи», «зеленый», «красный», «светодиод», «все», «светодиоды», «установи», «яркость», «красного», «зеленого», «светодиода», «ноль», «десять», «двадцать», «тридцать», «сорок», «пятьдесят», «шестьдесят», «семьдесят», «восемьдесят», «девяносто», «сто».
В папке config/test пакета abot_speech_to_text создадим обычный текстовый файл с этими словами. Назовём файл test_dictionary.txt:
робот
включи
выключи
зеленый
красный
светодиод
все
светодиоды
установи
яркость
красного
зеленого
светодиода
ноль
десять
двадцать
тридцать
сорок
пятьдесят
шестьдесят
семьдесят
восемьдесят
девяносто
сто
Чтобы вручную не создавать последовательность фонемов, воспользуемся утилитой text2dict из проекта ru4sphinx. Данный проект специально создан пользователями PocketSphinx для более удобной работы с русскоязычными моделями.
Сохраним этот проект куда-нибудь, например в домашнюю директорию на настольном компьютере. Утилита text2dict нужна нам единоразово, она не относится напрямую к софту нашего робота, и не стоит хранить ru4sphinx в рабочей области ROS. Склонируем проект и перейдём в папку text2dict.
git clone git@github.com:zamiron/ru4sphinx.git
cd ru4sphinx/text2dict
Запустим скрипт dict2transcript.pl с указанием двух путей. Первый путь — это путь до нашего текстового файла с выписанными словами, то есть test_dictionary.txt. Второй путь — это путь, куда сохранить файл с готовым словарём. Файл словаря имеет расширение .dic. Лучше указывать абсолютные пути до файлов. Сохраним словарь в ту же папку и назовём его test_dictionary.dic.
./dict2transcript.pl /home/ubuntu/abot/ros/src/abot_sound/abot_speech_to_text/config/test/test_dictionary.txt /home/ubuntu/abot/ros/src/abot_sound/abot_speech_to_text/config/test/test_dictionary.dic

Скрипт также создаст файл с акцентами test_dictionary.dic.accent, но на текущий момент он нам не нужен. Взглянем на сгенерированный файл словаря test_dictionary.dic:
включи f k ll uj ch ii
восемьдесят v oo ss i mm dd i ss i t
восемьдесят(2) v oo ss i mm ss i t
все f ss jo
все(2) f ss je
выключи v yy k ll uj ch i
двадцать d v aa c ay tt
девяносто dd i vv i n oo s t ay
десять dd je ss i tt
зеленого zz i ll jo n ay v ay
зеленый zz i ll jo n y j
красного k r aa s n ay v ay
красный k r aa s n y j
ноль n oo ll
пятьдесят pp i tt dd i ss ja t
пятьдесят(2) pp i ss ja t
робот r oo b ay t
светодиод s vv i t ay dd i oo t
светодиода s vv je t ay dd i ay d ay
светодиоды s vv je t ay dd i ay d y
семьдесят ss je mm dd i ss i t
семьдесят(2) ss je mm ss i t
сорок s oo r ay k
сорок(2) s a r oo k
сто s t oo
тридцать t rr ii c ay tt
установи u s t ay n a vv ii
шестьдесят sh y ss tt dd i ss ja t
шестьдесят(2) sh y z dd i ss ja t
шестьдесят(3) sh y ss ja t
яркость j ja r k ay ss tt
Для всех наших слов скрипт подготовил последовательность фонемов.
Скрипт KWS
Сейчас у нас есть акустическая модель, фонетический словарь и список ключевых фраз, и мы можем написать ноду ROS для режима Keyword Spotting (KWS) в PocketSphinx. Назовём эту ноду kws_control.
Так как мы используем Python-обёртку для PocketSphinx, писать ROS-ноду будем на Python. Начиная с дистрибутива Noetic в системе ROS используется только Python 3.
В папке scripts пакета abot_speech_to_text созадим новый исходный Python-файл kws_control.py:
#!/usr/bin/env python
# coding: utf-8
import rospy
from std_msgs.msg import String
from audio_common_msgs.msg import AudioData
from pocketsphinx import Decoder
class KWSDetection(object):
def __init__(self):
rospy.init_node('kws_control')
rospy.on_shutdown(self.shutdown)
self._kws_data_pub = rospy.Publisher('/abot/stt/kws_data', String, queue_size=10)
self._hmm = rospy.get_param('~hmm')
self._dict = rospy.get_param('~dict')
self._kws = rospy.get_param('~kws')
self._buffer_index = 0
self._buffer = bytearray()
self.startRecognizer()
def startRecognizer(self):
config = Decoder.default_config()
config.set_string('-hmm', self._hmm)
config.set_string('-dict', self._dict)
config.set_string('-kws', self._kws)
self._decoder = Decoder(config)
self._decoder.start_utt()
rospy.loginfo("KWS control node: Decoder started successfully")
rospy.Subscriber('/audio', AudioData, self.makeBuffer)
rospy.spin()
def makeBuffer(self, audio_msg):
self._buffer += audio_msg.data
self._buffer_index = self._buffer_index + 1
if self._buffer_index == 3:
self.processAudio(self._buffer)
self._buffer = bytearray()
self._buffer_index = 0
def processAudio(self, audio_buffer):
self._decoder.process_raw(audio_buffer, False, False)
if self._decoder.hyp() is not None:
for seg in self._decoder.seg():
rospy.logwarn("Detected key words: %s ", seg.word)
self._decoder.end_utt()
msg = seg.word
self._kws_pub.publish(msg)
self._decoder.start_utt()
@staticmethod
def shutdown():
rospy.loginfo("KWS control node: Stop KWSDetection")
rospy.sleep(1)
if __name__ == "__main__":
KWSDetection()
Разберёмся, как работает программа.
Мы создали класс KWSDetection, экземпляр которого при инициализации cоздаст ROS-ноду kws_control.
class KWSDetection(object):
def __init__(self):
rospy.init_node('kws_control')
rospy.on_shutdown(self.shutdown)
При инициализации нода загрузит с параметрического сервера ROS пути до файлов акустической модели, файла словаря и до списка ключевых слов:
self._hmm = rospy.get_param('~hmm')
self._dict = rospy.get_param('~dict')
self._kws = rospy.get_param('~kws')
Благодаря параметрическому серверу мы сможем указывать пути до файлов через launch-файл. Это очень удобно, например, если мы захотим использовать новый словарь или ключевые слова, не меняя при этом код программы.
Пусть при нахождении в речи ключевого слова оно будет опубликовано в топик /abot/stt/kws_data сообщением типа String.
self._kws_data_pub = rospy.Publisher('/abot/stt/kws_data', String, queue_size=10)
Создаём новый декодер движка PocketSphinx. В конфигурации декодера указываем пути до акустической модели, фонетического словаря и списка ключевых слов. Все остальные параметры в конфигурации (а их там около полусотни) оставляем по умолчанию. Запускаем декодер.
config = Decoder.default_config()
config.set_string('-hmm', self._hmm)
config.set_string('-dict', self._dict)
config.set_string('-kws', self._kws)
self._decoder = Decoder(config)
self._decoder.start_utt()
rospy.loginfo("KWS control node: Decoder started successfully")
Подписываемся на топик /audio, который содержит полученные с микрофона аудиоданные, и заставлем ноду kws_control крутиться в бесконечном цикле.
rospy.Subscriber('/audio', AudioData, self.makeBuffer)
rospy.spin()
Декодер движка PocketSphinx проанализирует столько семплов, сколько мы ему отправим. В топике /audio данные появляются по 160 семплов каждые 10 мс. Но 160 — слишком мало, рекомендуется больше. Мы будем отправлять в декодер в три раза больше данных — 960 байт или 480 семплов.
Создаём байтовый буфер, содержащий по три сообщения из топика /audio. Каждое четвёртое сообщение отправляет буфер на обработку.
def makeBuffer(self, audio_msg):
self._buffer += audio_msg.data
self._buffer_index = self._buffer_index + 1
if self._buffer_index == 3:
self.processAudio(self._buffer)
self._buffer = bytearray()
self._buffer_index = 0
Сформированный аудиобуфер отправляется в декодер PocketSphinx:
self._decoder.process_raw(audio_buffer, False, False)
При обнаружении в речи ключевого слова или фразы останавливаем декодер, публикуем в топик /abot/stt/kws_data строку с тем, что нашли, и запускаем декодер по новой.
if self._decoder.hyp() is not None:
for seg in self._decoder.seg():
rospy.logwarn("Detected key words: %s ", seg.word)
self._decoder.end_utt()
msg = seg.word
self._kws_data_pub.publish(msg)
self._decoder.start_utt()
Во время работы запущенный декодер PocketSphinx генерирует море информации в лог. Часть информации нам полезна, другая — нет. Чтобы не потеряться в потоке информации в логе, мы будем выводить выявленные декодером слова другим цветом, например жёлтым. Жёлтый цвет в ROS служит для вывода предупреждений (Warnings). Для этого воспользуемся функцией rospy.logwarn.
Нода готова, собираем проект:
catkin_make
Запуск Keyword Spotting (KWS)
Запустим ноду поиска по ключевым словам и протестируем её.
Добавим новые строки в launch-файл abot_speech_to_text.launch. Запустим новую ноду kws_control с параметрами путей до модели, словаря и списка ключевых слов:
<arg name="hmm" default="$(find abot_speech_to_text)/model/zero_ru_cont_8k_v3/zero_ru.cd_cont_4000" />
<arg name="kws" default="$(find abot_speech_to_text)/config/test/test_kwslist.kwslist" />
<arg name="dict" default= "$(find abot_speech_to_text)/config/test/test_dictionary.dic" />
<node name="kws_control" pkg="abot_speech_to_text" type="kws_control.py" output="screen" >
<param name="hmm" value="$(arg hmm)"/>
<param name="dict" value="$(arg dict)"/>
<param name="kws" value="$(arg kws)"/>
</node>
Запускаем обновлённый launch-файл с двумя нодами audio_capture и kws_control.
source devel/setup.bash
roslaunch abot_speech_to_text abot_speech_to_text.launch

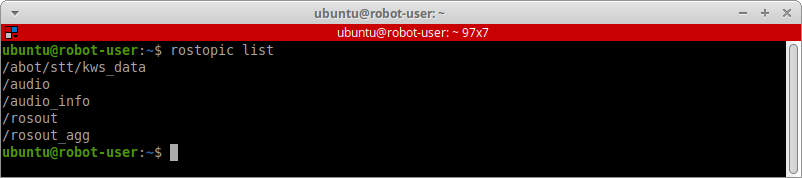
Проверим в отдельном терминале, что появился новый топик /abot/stt/kws_data:
rostopic list
Попробуем сказать ключевое слово «Робот» в микрофон и проверим, распознала ли его наша программа.
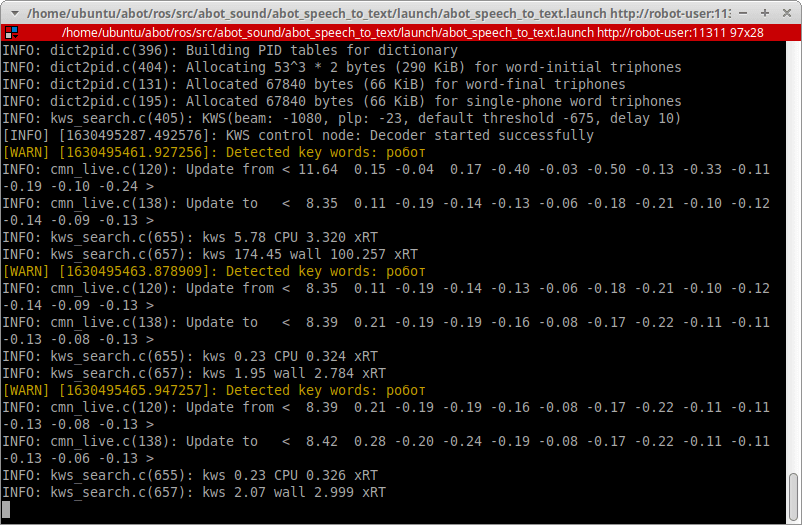
Режим Keyword Spotting работает! Вы можете повторять ваше кодовое слово сколько угодно раз. Также можно попробовать вставить ключевое слово в непрерывную речь и посмотреть на количество ложных срабатываний. Если оно велико, то нужно увеличить пороговое значение для вашего кодового слова файле в kwslist.
Сейчас граф наших звуковых нод и топиков выглядит следующим образом:
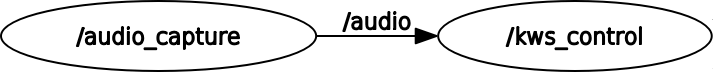
Построение грамматики
Мы научились выделять ключевые фразы в речи. Но ключевое слово «Робот» является лишь началом голосовой команды. Чтобы разобрать все другие слова и построить из них предложение, роботу нужна формальная грамматика.
Наш робот будет использовать не вероятностную грамматику N-gramm, а регулярную грамматику FSG. То есть все предложения (команды), которые робот должен уметь распознавать, строго определены.
Для задания FSG-грамматик в PocketSphinx используются файлы формата JSGF (Java Speech Grammar Format) со своим уникальным синтаксисом. Синтаксис довольно простой, и разобраться с ним несложно.
Файлы грамматик обычно имеют расширение .gram. В папке config/test пакета abot_speech_to_text cоздаём новый файл грамматики test_gram.gram, в котором согласно JSGF-синтаксису описываем формальный язык нашего робота:
#JSGF V1.0;
grammar robot_cmd;
public <commands> = <command> ;
<command> = <command_1> | <command_2> ;
<command_1> = <c1_action> (( <c1_subject_color> светодиод ) | все светодиоды ) ;
<c1_action> = включи | выключи ;
<c1_subject_color> = зеленый | красный ;
<command_2> = установи яркость <c2_subject_color> светодиода <c2_brightness_percent> ;
<c2_subject_color> = зеленого | красного ;
<c2_brightness_percent> = ноль | десять | двадцать | тридцать | сорок | пятьдесят | шестьдесят | семьдесят | восемьдесят | девяносто | сто ;
У нашего робота одна грамматика, которая называется robot_cmd и содержит единственное грамматическое правило commands.
Каждую из наших 28 возможных голосовых команд можно грамматически структурировать. По сути, мы имеем две базовые команды command_1 и command_2, описывающие два сложных предложения.
Первое предложение может включить/выключить зелёный/красный светодиод или включить/выключить все светодиоды разом. Второе предложение управляет яркостью определённого светодиода.
Ретрансляция аудио
Сейчас в наш KWS-декодер приходит аудиозапись /audio. Если декодер находит в ней ключевое слово, нода kws_control отправляет это слово в топик /abot/stt/kws_data. Больше в программе пока ничего не происходит.
Поведение нашей программы нужно скорректировать так, чтобы при обнаружении ключевого слова режим KWS останавливался и запускался новый режим распозавания по грамматике. Назовём этот режим ASR (Automatic Speech Recognition). При обраружении ключевого слова нам нужно остановить KWS-декодер и перенаправить весь аудиопоток в декодер ASR. Если декодер ASR не обнаружит никакой голосовой команды, произнесённой после ключевого слова, то KWS-декодер запустится заново.
Изменённый скрипт kws_control.py выглядит следующим образом:
#!/usr/bin/env python
# coding: utf-8
import rospy
from std_msgs.msg import String, Empty
from audio_common_msgs.msg import AudioData
from pocketsphinx import Decoder
class KWSDetection(object):
def __init__(self):
rospy.init_node('kws_control')
rospy.on_shutdown(self.shutdown)
self._kws_data_pub = rospy.Publisher('/abot/stt/kws_data', String, queue_size=10)
self._grammar_audio_pub = rospy.Publisher('/abot/stt/grammar_audio', AudioData, queue_size=10)
self._hmm = rospy.get_param('~hmm')
self._dict = rospy.get_param('~dict')
self._kws = rospy.get_param('~kws')
self._buffer_index = 0
self._buffer = bytearray()
self._kws_found = False
self.startRecognizer()
def startRecognizer(self):
config = Decoder.default_config()
config.set_string('-hmm', self._hmm)
config.set_string('-dict', self._dict)
config.set_string('-kws', self._kws)
self._decoder = Decoder(config)
self._decoder.start_utt()
rospy.loginfo("KWS control node: Decoder started successfully")
rospy.Subscriber('/audio', AudioData, self.makeBuffer)
rospy.Subscriber('/abot/stt/grammar_not_found', Empty, self.grammarCheckCallback)
rospy.spin()
def grammarCheckCallback(self, empty_msg):
self._kws_found = False
rospy.logwarn("KWS control node: Stop ASR audio transmission")
def makeBuffer(self, audio_msg):
self._buffer += audio_msg.data
self._buffer_index = self._buffer_index + 1
if self._buffer_index == 3:
self.processAudio(self._buffer)
self._buffer = bytearray()
self._buffer_index = 0
def processAudio(self, audio_buffer):
self._decoder.process_raw(audio_buffer, False, False)
if self._decoder.hyp() is not None:
for seg in self._decoder.seg():
rospy.logwarn("Detected key words: %s ", seg.word)
self._decoder.end_utt()
msg = seg.word
self._kws_data_pub.publish(msg)
self._kws_found = True
self._decoder.start_utt()
if self._kws_found is True:
msg = AudioData()
msg.data = audio_buffer
self._grammar_audio_pub.publish(msg)
@staticmethod
def shutdown():
rospy.loginfo("KWS control node: Stop KWSDetection")
rospy.sleep(1)
if __name__ == "__main__":
KWSDetection()
Какие изменения мы внесли?
Мы создали в ноде kws_control новый паблишер для ретрансляции аудиоданных в новый топик для ASR-режима. Топик назвали /abot/stt/grammar_audio.
self._grammar_audio_pub = rospy.Publisher('/abot/stt/grammar_audio', AudioData, queue_size=10)
Добавили булеву переменную для отслеживания, было ли найдено ключевое слово или нет:
self._kws_found = False
Если ключевое слово было найдено, начнётся ретрансляция аудио в /abot/stt/grammar_audio:
if self._kws_found is True:
msg = AudioData()
msg.data = audio_buffer
self._grammar_audio_pub.publish(msg)
Ещё мы подписались на топик, который сообщает нам, было ли найдено точное грамматическое предложение. Топик назвали /abot/stt/grammar_not_found. В него поступают пустые «сигнальные» сообщения типа Empty.
rospy.Subscriber('/abot/stt/grammar_not_found', Empty, self.grammarCheckCallback)
Если ASR-декодер не нашёл в ретранслированном аудио никаких предложений из грамматики, останавливаем трансляцию аудио:
def grammarCheckCallback(self, empty_msg):
self._kws_found = False
rospy.logwarn("KWS control node: Stop ASR audio transmission")
Можно заново запустить ноды файлом abot_speech_to_text.launch и проверить, появились ли новые топики /abot/stt/grammar_audio и /abot/stt/grammar_not_found:

Скрипт Automatic Speech Recognition (ASR)
Напишем финальную ноду ROS для автоматической системы распознавания речи (ASR) по нашей грамматике. Назовем её asr_control.
В папке scripts пакета abot_speech_to_text созадим новый исходный Python-файл asr_control.py:
#!/usr/bin/env python
# coding: utf-8
import rospy
from std_msgs.msg import String, Empty
from audio_common_msgs.msg import AudioData
from pocketsphinx import Decoder, Jsgf
class ASRControl(object):
def __init__(self):
rospy.init_node("asr_control")
rospy.on_shutdown(self.shutdown)
self._grammar_data_pub = rospy.Publisher("/abot/stt/grammarf_data", String, queue_size=10)
self._grammar_not_found_pub = rospy.Publisher('/abot/stt/grammar_not_found', Empty, queue_size=10)
self._hmm = rospy.get_param('~hmm')
self._dict = rospy.get_param('~dict')
self._gram = rospy.get_param('~gram')
self._rule = rospy.get_param('~rule')
self._in_speech_bf = False
self.startRecognizer()
def startRecognizer(self):
config = Decoder.default_config()
config.set_string('-hmm', self._hmm)
config.set_string('-dict', self._dict)
self._decoder = Decoder(config)
jsgf = Jsgf(self._gram + '.gram')
rule = jsgf.get_rule(rospy.get_param('~grammar') + '.' + self._rule)
fsg = jsgf.build_fsg(rule, self._decoder.get_logmath(), 7.5)
fsg.writefile(self._gram + '.fsg')
self._decoder.set_fsg(self._gram, fsg)
self._decoder.set_search(self._gram)
self._decoder.start_utt()
rospy.loginfo("ASR control node: Decoder started successfully")
rospy.Subscriber("/abot/stt/grammar_audio", AudioData, self.processAudio)
rospy.spin()
def processAudio(self, audio_msg):
self._decoder.process_raw(audio_msg.data, False, False)
if self._decoder.get_in_speech() != self._in_speech_bf:
self._in_speech_bf = self._decoder.get_in_speech()
if not self._in_speech_bf:
self._decoder.end_utt()
if self._decoder.hyp() is not None:
msg = self._decoder.hyp().hypstr
rospy.logwarn('ASR control node: OUTPUT - \"' + msg + '\"')
self._grammar_data_pub.publish(msg)
else:
rospy.logwarn("ASR control node: No possible grammar found")
msg = Empty()
self._grammar_not_found_pub.publish(msg)
self._decoder.start_utt()
@staticmethod
def shutdown():
rospy.loginfo("ASR control node: Stop ASRControl")
rospy.sleep(1)
if __name__ == "__main__":
ASRControl()
Разберёмся, как работает программа.
Мы создали класс ASRControl, экземпляр которого при инициализации cоздаст ROS-ноду asr_control.
class ASRControl(object):
def __init__(self):
rospy.init_node("asr_control")
rospy.on_shutdown(self.shutdown)
Пусть при обнаружении в речи голосовой команды из нашей грамматики она будет опубликована в топик /abot/stt/grammar_data сообщением типа String. А если не будет найдено, то мы отправим пустое сообщение в топик /abot/stt/grammar_not_found с сигналом об остановке трансляции аудио.
self._grammar_data_pub = rospy.Publisher("/abot/stt/grammar_data", String, queue_size=10)
self._grammar_not_found_pub = rospy.Publisher('/abot/stt/grammar_not_found', Empty, queue_size=10)
При инициализации нода загрузит с параметрического сервера ROS пути до файлов акустической модели, файла словаря, а также имя грамматики и грамматического правила. В этот раз список ключевых слов нам уже не нужен.
self._hmm = rospy.get_param('~hmm')
self._dict = rospy.get_param('~dict')
self._gram = rospy.get_param('~gram')
self._rule = rospy.get_param('~rule')
Подписываемся на топик /abot/stt/grammar_audio, который содержит ретранслированный аудиопоток после программы KWS.
rospy.Subscriber("/abot/stt/grammar_audio", AudioData, self.processAudio)
rospy.spin()
Как и в KWS-программе, создаём новый декодер PocketSphinx с новой конфигурацией, на этот раз с указанием пути до файла JSFG. Генерируем нашу регулярную FSG-грамматику из JSFG-файла. Запускаем декодер.
config = Decoder.default_config()
config.set_string('-hmm', self._hmm)
config.set_string('-dict', self._dict)
self._decoder = Decoder(config)
jsgf = Jsgf(self._gram + '.gram')
rule = jsgf.get_rule(rospy.get_param('~grammar') + '.' + self._rule)
fsg = jsgf.build_fsg(rule, self._decoder.get_logmath(), 7.5)
fsg.writefile(self._gram + '.fsg')
self._decoder.set_fsg(self._gram, fsg)
self._decoder.set_search(self._gram)
self._decoder.start_utt()
Если ASR-декодер обнаружит какое-либо предложение из нашей грамматики, публикуем его в топик /abot/stt/grammar_data. Иначе отправляем сигнал, что ничего не найдено.
def processAudio(self, audio_msg):
self._decoder.process_raw(audio_msg.data, False, False)
if self._decoder.get_in_speech() != self._in_speech_bf:
self._in_speech_bf = self._decoder.get_in_speech()
if not self._in_speech_bf:
self._decoder.end_utt()
if self._decoder.hyp() is not None:
msg = self._decoder.hyp().hypstr
rospy.logwarn('ASR control node: OUTPUT - \"' + msg + '\"')
self._grammar_data_pub.publish(msg)
else:
rospy.logwarn("ASR control node: No possible grammar found")
msg = Empty()
self._grammar_not_found_pub.publish(msg)
self._decoder.start_utt()
Запуск ASR
Скрипты написаны, теперь запустим их. Запускать будем одновременно оба режима: ASR и KWS будут работать в паре. Запускаем ноды всё тем же launch-файлом abot_speech_to_text.launch.
Запустим новую ноду asr_control с путями до акустической модели, фонетического словаря и файла грамматики. Также в аргументах зададим имя грамматики и грамматического правила. Итоговый файл запуска теперь выглядит так:
<launch>
<!-- Audio capture params -->
<arg name="device" default="plughw:1" />
<arg name="bitrate" default="160" />
<arg name="channels" default="1" />
<arg name="sample_rate" default="16000" />
<arg name="sample_format" default="S16LE" />
<arg name="dst" default="appsink" />
<arg name="format" default="wave" />
<!-- Pocketsphinx params -->
<arg name="hmm" default="$(find abot_speech_to_text)/model/zero_ru_cont_8k_v3/zero_ru.cd_cont_4000" />
<arg name="dict" default= "$(find abot_speech_to_text)/config/test/test_dictionary.dic" />
<arg name="kws" default="$(find abot_speech_to_text)/config/test/test_kwslist.kwslist" />
<arg name="gram" default="$(find abot_speech_to_text)/config/test/test_gram" />
<arg name="grammar" default="robot_cmd" />
<arg name="rule" default="commands" />
<node name="asr_control" pkg="abot_speech_to_text" type="asr_control.py" output="screen" >
<param name="hmm" value="$(arg hmm)" />
<param name="dict" value="$(arg dict)" />
<param name="gram" value="$(arg gram)" />
<param name="grammar" value="$(arg grammar)" />
<param name="rule" value="$(arg rule)" />
</node>
<node name="kws_control" pkg="abot_speech_to_text" type="kws_control.py" output="screen" >
<param name="hmm" value="$(arg hmm)" />
<param name="dict" value="$(arg dict)" />
<param name="kws" value="$(arg kws)" />
</node>
<node name="audio_capture" pkg="audio_capture" type="audio_capture" output="screen" >
<param name="bitrate" value="$(arg bitrate)" />
<param name="device" value="$(arg device)" />
<param name="channels" value="$(arg channels)" />
<param name="sample_rate" value="$(arg sample_rate)" />
<param name="sample_format" value="$(arg sample_format)" />
<param name="format" value="$(arg format)" />
<param name="dst" value="$(arg dst)" />
</node>
</launch>
Запускаем оба режима:
source devel/setup.bash
roslaunch abot_speech_to_text abot_speech_to_text.launch
В новом терминале взглянем на новые топики:
rostopic list

Попробуем сказать какую-либо из наших голосовых команд в микрофон.
Команду следует говорить единым слитным предложением, не останавливаясь и не запинаясь. Говорите команду роботу так, как вы бы сказали её человеку.

Отлично, наш ASR-декодер распознаёт команды!
Если команда успешно определилась в речевом потоке, она появится строкой в нашем топике для вывода распознанных команд /abot/stt/grammar_data:
rostopic echo /abot/stt/grammar_data
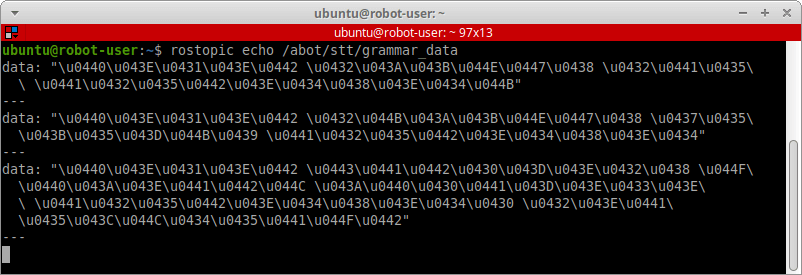
Это важно! Мониторя топик ROS, куда поступают сообщения типа String, вы не увидете русских слов или кириллических символов. В ROS все сообщения типа String, кроме латиницы, перед отправкой в топик кодируются в формат ASCII.
Сейчас граф наших звуковых нод и топиков выглядит следующим образом:

Обработчик команд
Итак, что у нас есть на данный момент? Сейчас мы имеем работающий микрофон, данные с которого поступают в ноды «Speech-to-Text». В свою очередь, ноды выявляют в записанной речи заданные нами голосовые команды.
Теперь нужно создать обработчик этих самых голосовых команд. Просто распознать голосовую команду мало — робот должен на неё правильно среагировать, то есть сделать то, что в ней указано.
Подключаем светодиоды
В этом примере все придуманные нами голосовые команды связаны исключительно с управлением двумя светодиодами — зелёным и красным. Давайте подключим их к нашему роботу!
Используем два обычных светодоида 5 мм в формате Troyka-модулей.

Часть голосовых команд управляет яркостью светодиодов. Для этого нам нужен ШИМ-сигнал. Все аппаратные каналы с ШИМ на плате Raspberry Pi у нас заняты моторами, а программный ШИМ мы даже не будем расматривать.
На нашей Raspberry Pi установлен модуль Troyka HAT, у которого на борту есть расширитель GPIO-портов на отдельном микроконтроллере STM32 с управлением по I²C. Расширитель даёт восемь дополнительных пинов ввода-вывода с аппаратной поддержкой 12-битного АЦП и 16-битного ШИМ, которыми мы и воспользуемся.
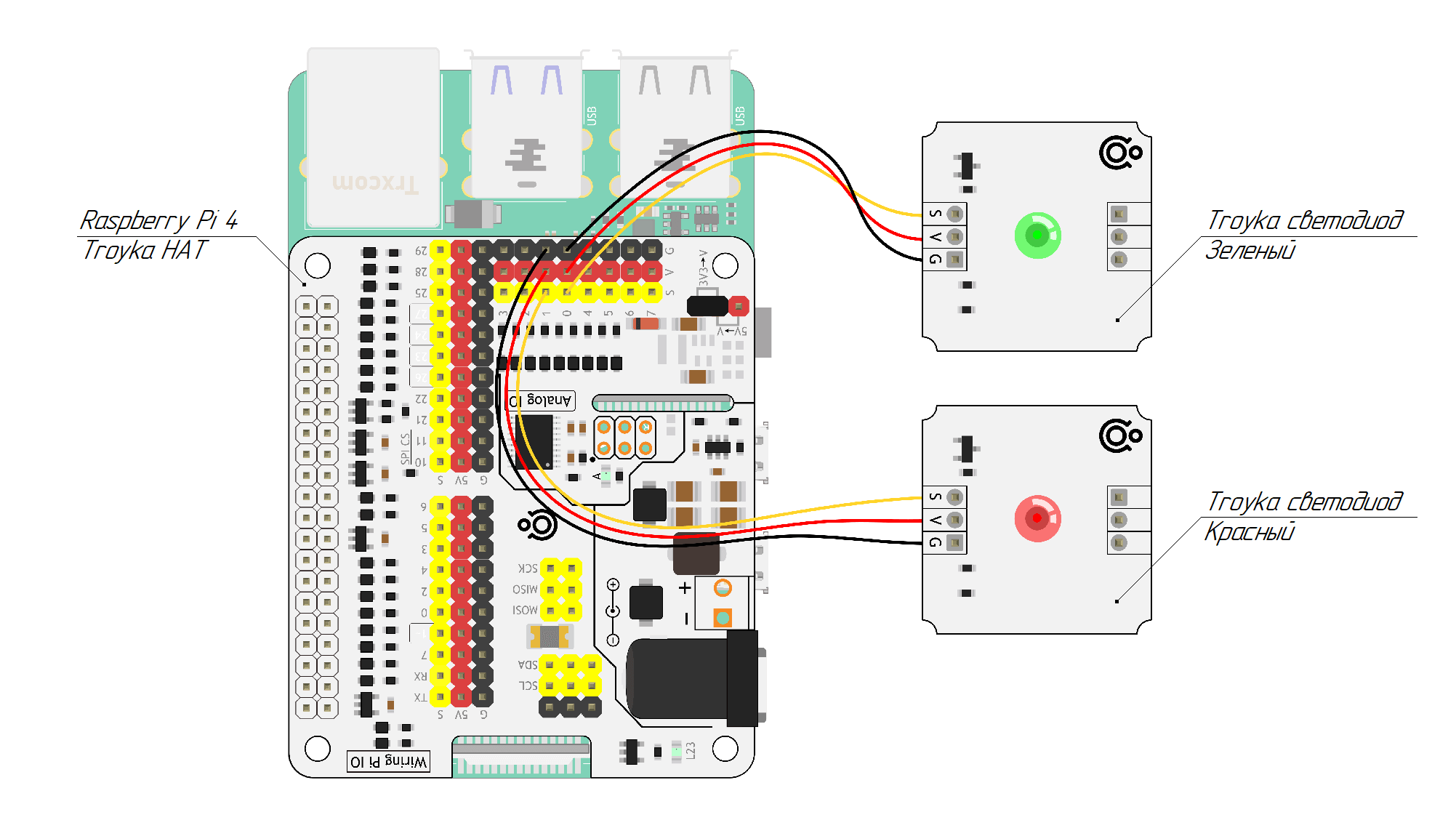
Схема подключения предельно проста. Зелёный светодиод подключим к нулевому пину расширителя, а красный — к первому пину. Перемычкой установим напряжение питания на гребенке пинов расширителя в 3,3 В.

Пакет abot_speech_command
Создадим новый ROS-пакет в нашем стеке пакетов abot_sound. Назовём его, например, abot_speech_command. В этом пакете мы будем хранить ноды, которые отвечают за обработку голосовых команд на роботе.
В качестве пакетов зависимостей для abot_speech_command устанавливаем:
В пакете создадим две папки: src для хранения исходных файлов нод и launch для их запуска. В папке src создадим подпапку test, куда поместим ноду для обработки голосовых команд в этом конкретном примере с двумя светодиодами.
Библиотека для Troyka HAT
Обработчики голосовых команд мы будем писать на С++, хотя вы можете написать их и на Python, как вам удобно — ROS поддерживает оба языка.
Расширитель GPIO-портов на плате Troyka HAT работает по интерфейсу I²C, и для работы с ним нужна специальная библиотека. Мы будем использовать библиотеку TroykaHatCpp на С++.
Данная библиотека является надстройкой над стандартной библиотекой WiringPi, которая уже должна стоять в вашей системе. О том, как установить WiringPi, мы рассказывали в отдельной главе в прошлой части проекта.
На Raspberry Pi скачиваем TroykaHatCpp из репозитория куда-нибудь, например в домашнюю директорию.
git clone git@github.com:amperka/TroykaHatCpp.git
Переходим в скачанную папку, компилируем и устанавливаем библиотеку:
cd TroykaHatCpp
make
sudo make install
Нода test_command_executor
Сделаем ноду ROS для обработки тестовых голосовых команд. Назовём её test_command_executor.
В пакете abot_speech_command в папке src/test создадим исходный файл С++ test_command_executor.cpp:
#include <string>
#include <vector>
#include <ros/ros.h>
#include <std_msgs/String.h>
#include <wiringPi.h>
#include <GpioExpanderPi.h>
constexpr uint8_t EXPANDER_GREEN_LED_PIN = 0;
constexpr uint8_t EXPANDER_RED_LED_PIN = 1;
const std::vector<std::string> VOICE_COMMANDS = {
"включи зеленый светодиод",
"выключи зеленый светодиод",
"включи красный светодиод",
"выключи красный светодиод",
"включи все светодиоды",
"выключи все светодиоды",
"установи яркость зеленого светодиода ноль",
"установи яркость зеленого светодиода десять",
"установи яркость зеленого светодиода двадцать",
"установи яркость зеленого светодиода тридцать",
"установи яркость зеленого светодиода сорок",
"установи яркость зеленого светодиода пятьдесят",
"установи яркость зеленого светодиода шестьдесят",
"установи яркость зеленого светодиода семьдесят",
"установи яркость зеленого светодиода восемьдесят",
"установи яркость зеленого светодиода девяносто",
"установи яркость зеленого светодиода сто",
"установи яркость красного светодиода ноль",
"установи яркость красного светодиода десять",
"установи яркость красного светодиода двадцать",
"установи яркость красного светодиода тридцать",
"установи яркость красного светодиода сорок",
"установи яркость красного светодиода пятьдесят",
"установи яркость красного светодиода шестьдесят",
"установи яркость красного светодиода семьдесят",
"установи яркость красного светодиода восемьдесят",
"установи яркость красного светодиода девяносто",
"установи яркость красного светодиода сто"
};
class TestCommandExecutor {
public:
TestCommandExecutor();
private:
ros::NodeHandle _node;
ros::Subscriber _grammar_sub;
GpioExpanderPi _expander;
void executeCommand(uint8_t command_number);
void grammarCallback(const std_msgs::String::ConstPtr& msg);
};
TestCommandExecutor::TestCommandExecutor() {
_grammar_sub = _node.subscribe("/abot/stt/grammar_data", 1, &TestCommandExecutor::grammarCallback, this);
if (!_expander.begin())
throw std::runtime_error("Test Command Executor node: Expander launch error!");
_expander.pinMode(EXPANDER_GREEN_LED_PIN, GPIO_PIN_OUTPUT);
_expander.pinMode(EXPANDER_RED_LED_PIN, GPIO_PIN_OUTPUT);
}
void TestCommandExecutor::grammarCallback(const std_msgs::String::ConstPtr& msg) {
std::string grammar_string = msg->data.c_str();
uint8_t total_commands = VOICE_COMMANDS.size();
for (uint8_t i = 0; i < total_commands; i++)
if (grammar_string == VOICE_COMMANDS[i])
executeCommand(i);
}
void TestCommandExecutor::executeCommand(uint8_t command_number) {
if (command_number == 0)
_expander.digitalWrite(EXPANDER_GREEN_LED_PIN, HIGH);
else if (command_number == 1)
_expander.digitalWrite(EXPANDER_GREEN_LED_PIN, LOW);
else if (command_number == 2)
_expander.digitalWrite(EXPANDER_RED_LED_PIN, HIGH);
else if (command_number == 3)
_expander.digitalWrite(EXPANDER_RED_LED_PIN, LOW);
else if (command_number == 4) {
_expander.digitalWrite(EXPANDER_GREEN_LED_PIN, HIGH);
_expander.digitalWrite(EXPANDER_RED_LED_PIN, HIGH);
} else if (command_number == 5) {
_expander.digitalWrite(EXPANDER_GREEN_LED_PIN, LOW);
_expander.digitalWrite(EXPANDER_RED_LED_PIN, LOW);
} else if (command_number >= 6 && command_number < 17) {
uint8_t command_in_order = command_number - 6;
uint8_t percent = command_in_order * 10;
float pwm = 255.0 * percent / 100;
_expander.analogWrite(EXPANDER_GREEN_LED_PIN, (uint8_t)pwm);
} else if (command_number >= 17 && command_number < 28) {
uint8_t command_in_order = command_number - 17;
uint8_t percent = command_in_order * 10;
float pwm = 255.0 * percent / 100;
_expander.analogWrite(EXPANDER_RED_LED_PIN, (uint8_t)pwm);
}
}
int main(int argc, char **argv) {
ros::init(argc, argv, "test_command_executor");
TestCommandExecutor testCommandExecutor;
ROS_INFO("Test Command Executor node: Start");
ros::spin();
return 0;
}
Как работает эта нода?
Для работы с расширетелем портов на Troyka HAT подключаем нужные заголовочные файлы библиотек WiringPi и TroykaHatCpp:
#include <wiringPi.h>
#include <GpioExpanderPi.h>
Задаём номера пинов расширителя, к которым подключены наши светодиоды. Зелёный к пину 0, красный к пину 1:
constexpr uint8_t EXPANDER_GREEN_LED_PIN = 0;
constexpr uint8_t EXPANDER_RED_LED_PIN = 1;
Создаём контейнер, который содержит все 28 тестовых голосовых команд в виде строк:
const std::vector<std::string> VOICE_COMMANDS = {};
Создаём простой класс TestCommandExecutor с методом для обработки голосовых команд executeCommand и объектом типа GpioExpanderPi для работы с расширителем портов.
class TestCommandExecutor {
public:
TestCommandExecutor();
private:
ros::NodeHandle _node;
ros::Subscriber _grammar_sub;
GpioExpanderPi _expander;
void executeCommand(uint8_t command_number);
void grammarCallback(const std_msgs::String::ConstPtr& msg);
};
В конструкторе класса подписываемся нодой на топик /abot/stt/grammar_data, куда поступают наши распознанные движком PocketSphinx предложения. Запускаем I²C-общение между Raspberry Pi и расширителем портов на Troyka HAT. Устанавливаем режим работы пинов расширителя cо светодиодами в GPIO_PIN_OUTPUT:
TestCommandExecutor::TestCommandExecutor() {
_grammar_sub = _node.subscribe("/abot/stt/grammar_data", 1, &TestCommandExecutor::grammarCallback, this);
if (!_expander.begin())
throw std::runtime_error("Test Command Executor node: Expander launch error!");
_expander.pinMode(EXPANDER_GREEN_LED_PIN, GPIO_PIN_OUTPUT);
_expander.pinMode(EXPANDER_RED_LED_PIN, GPIO_PIN_OUTPUT);
}
Каждый раз, когда в топике /abot/stt/grammar_data появляется новая распознанная голосовая команда, мы определяем её номер i среди всех команд в контейнере VOICE_COMMANDS. Вызываем функцию executeCommand с номером команды.
void TestCommandExecutor::grammarCallback(const std_msgs::String::ConstPtr& msg) {
std::string grammar_string = msg->data.c_str();
uint8_t total_commands = VOICE_COMMANDS.size();
for (uint8_t i = 0; i < total_commands; i++)
if (grammar_string == VOICE_COMMANDS[i])
executeCommand(i);
}
В зависимости от номера команды функция executeCommand будет производить нужные нам действия со светодиодами: выключать-выключать их функцией digitalWrite или изменять яркость ШИМ-сигнала функцией analogWrite.
Добавим новый исполняемый файл С++ в правило сборки CMakelists.txt в нашем пакете abot_speech_command:
add_executable(test_command_executor src/test/test_command_executor.cpp)
target_link_libraries(test_command_executor ${catkin_LIBRARIES} -lwiringPi -lGpioExpanderPi)
Соберём проект c новой нодой:
catkin_make
Запуск обработчика команд
Пришло время протестить голосовое управление светодоиодами!
На Raspberry Pi в одном терминале запустим все ноды пакета abot_speech_to_text уже привычным файлом abot_speech_to_text.launch:
source devel/setup.bash
roslaunch abot_speech_to_text abot_speech_to_text.launch
В другом терминале из пакета abot_speech_command вручную запустим тестовую ноду обработчика команд test_command_executor:
source devel/setup.bash
rosrun abot_speech_command test_command_executor

Граф нод и топиков теперь выглядит следующим образом:
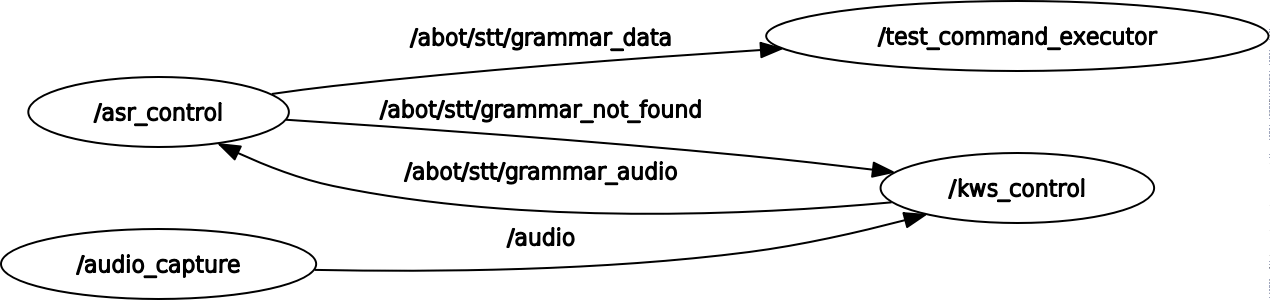
Попробуем управлять нашими светодоидами голосовыми командами.
Для примера работы мы записали видео с 13 командами, которые произносятся тремя людьми на разном расстоянии от микрофона:
Всё работает практически идеально! Команды распознаются очень быстро и точно.
Да, ошибки случаются. Например, когда программа путает похожие слова типа «включить» и «выключить». Чтобы этого избежать, нужно лишь громко и внятно говорить команды.
Распознавание речи у нас дикторонезависимое. Однако PocketSphinx — свободное программное обеспечение, и русскоязычная акустическая модель для него обучалась сообществом, причём преимущественно взрослыми мужчинами. Поэтому распознавание детских и чересчур женственных голосов может хромать.
Резюмируя сказанное, система PocketSphinx идеальна при условии, что она бесплатна и мы можем легко запустить её на Raspberry Pi!
Продолжение следует
На этом пока всё! В следующей части проекта мы приделаем роботу систему синтеза речи, чтобы он мог откликаться своим цифровым голосом, а заодно обучим его навигационным голосовым командам.