Как сделать робота на ROS своими руками. Часть 4: синтез речи и голосовое управление
Привет!
В прошлой части проекта мы запрограммировали систему распознавания речи и проверили, как наш робот исполняет тестовые голосовые команды.
Теперь мы сделаем роботу систему синтеза речи «Text-to-Speech», чтобы он мог откликаться на наши команды, а заодно обучим его навигационным голосовым командам. Поехали!
Содержание
- Звуковые устройства
- Распознавание речи
- Пример приложения «Speech-to-Text»
- Синтез речи
- Голосовое управление роботом
- Заключение
Синтез речи
Отлично, теперь робот может нас слышать и выполнять голосовые команды. Но что если мы хотим, чтобы робот нам отвечал, и сформировалось некое подобие диалога между роботом и человеком?
Для воспроизведения компьютером человеческого голоса необходим синтезатор речи. Подобные системы часто называют просто «Text-to-Speech», или сокращённо TTS.
Системы речевого синтеза работают так же, как «Speech-to-Text», только в обратном порядке.
В «Speech-to-Text» мы как бы разбиваем звук на куски: записываем речь, находим в ней акустические признаки и форманты. Затем по признакам определяем фонемы, из последовательности которых определяем вероятные слова и формируем из них предложения согласно грамматике.
В «Text-to-Speech» же всё наоборот: мы собираем звук по кусочкам — разбиваем предложение на слова, делим их на слоги и фонемы. Затем строим по ним последовательность формант и синтезируем речь из последовательности тонов, шумов и голосовых формант.
Системы TTS, как и «Speech-to-Text», используют разные методы и техники, в том числе скрытые Марковские модели и нейросети. Мы не будем вдаваться в то, как работают системы «Text-to-Speech» и какова их классификация, а лучше сразу рассмотрим применение программного обеспечения.
Выбор системы синтеза речи
Выберем программное обеспечение для синтеза речи на нашем роботе.
Готовых систем синтеза речи столь же много, как и систем распознавания речи. Системы «Text-to-Speech» тоже отличаются производительностью и затачиваются под разные устройства.
При выборе системы «Text-to-Speech» нас в первую очередь интересуют следующие критерии:
- Язык. Раз наш робот распознаёт русский язык, то пусть и говорит на нём.
- Голоса. Было бы здорово, если бы робот мог говорить разными голосами, и у нас была возможность выбора тембра.
- Качество речи. Чем больше синтезированная речь похожа на человеческую, тем лучше.
- Требуемая вычислительная мощность. Программное обеспечение должно быть легковесным, ведь мы собираемся использовать его на Raspberry Pi, а не на мощном стационарном компьютере.
- Цена. Как всегда, мы хотим, чтобы синтез речи был для нас бесплатным или совсем недорогим.
Довольно часто у IT-гигантов системы «Speech-to-Text» и «Text-to-Speech» объединены в единый продукт. Все эти решения поставляются в виде облачных сервисов:
- Yandex.SpeechKit
- Amazon Polly
- Google Text-to-Speech
- IBM Watson Text to Speech
- Microsoft Azure Text to Speech
Принцип работы прост. Отправляете на сервер запрос, содержащий текст, который вы хотите воспроизвести, а в ответ получаете аудиофайл с синтезированной речью. Качество синтезированной облачным сервисом речи, как правило, очень высокое, особенно для английского языка.
Как и в случае со «Speech-to-Text», у всех облачных систем два главных минуса. Первый — необходимость постоянного подключения к интернету. Второй минус — это цена, ведь все облачные системы платные. Стоимость услуг зависит от количества символов в синтезируемом тексте.
Однако если в системе «Speech-to-Text» нам нужен был непрерывный анализ звука, то в «Text-to-Speech» можно существенно сократить объём запросов. Мы можем и вовсе качественно озвучить несколько десятков слов и предложений, сохранить их в виде аудиофайлов и больше не пользоваться сервисом.
В этом проекте мы на примере системы Amazon Polly расскажем, как сделать синтез голоса через интернет.
Мы нашли популярные бесплатные системы синтеза речи, которые работают оффлайн и распространяются как open-source:
- Festival Speech Synthesis System и Festvox
- Flite
- ESpeak
- FreeTTS
- MaryTTS
- Mozilla TTS
- RHVoice
- Mimic
- Silero
Систем и их разновидностей очень много. Одни легковесные, другие — нет. Некоторые системы используют Deep learning, и разобраться с ними без подготовки очень тяжело. Где-то есть поддержка русского языка, а где-то её нет. Помимо этого половину перечисленных систем довольно трудно интегрировать в ROS.
В итоге мы выбрали две оффлайн-системы: Festival и RHVoice. Прежде всего, из-за лёгкости их установки и настройки. К слову, в стеке ROS-пакетов audio_common уже есть поддержка Festival, и нужно только добавить русский язык. Ну а RHVoice можно просто установить пакетом из репозитория.
Итого мы рассмотрим три системы: Amazon Polly, Festival и RHVoice. Протестируем их и для каждой сделаем свою ноду. Все ноды будут взаимозаменяемыми, и вы сможете сами выбрать, какой вариант вам подходит лучше.
Пакет abot_text_to_speech
В стеке abot_sound создадим новый пакет. Назовём его abot_text_to_speech. Этот пакет будет отвечать за синтез речи в ROS и за работу систем «Text-to-Speech» на нашем роботе.
В пакете abot_text_to_speech создадим три папки: sounds для хранения звуковых файлов, launch для файлов запуска и scripts для файлов с исходным кодом на Python.
Оформляем файлы CMakeLists.txt и package.xml. В качестве пакетов зависимостей для abot_speech_to_text устанавливаем пакеты:
Для работы с AWS Polly нам понадобится сторонний Python-пакет boto3. В файл package.xml добавляем следующую строку:
<exec_depend>python3-boto3</exec_depend>
В папке launch-пакета abot_text_to_speech создадим пока что пустой файл запуска abot_text_to_speech.launch, которым мы будем запускать все ноды для синтеза и воспроизведения речи.
Собираем проект:
catkin_make
Запуск вывода звука
Синтезированная роботом речь должна как-то воспроизводиться на наших динамиках. Настроим воспроизведение звука в ROS. Для этого воспользуемся готовой нодой soundplay_node из пакета sound_play.
В файле abot_text_to_speech.launch запустим ноду soundplay_node со следующим параметром:
<launch>
<arg name="device" default="plughw:2" />
<node name="soundplay_node" pkg="sound_play" type="soundplay_node.py" output="screen" >
<param name="device" value="$(arg device)" />
</node>
</launch>
Здесь параметром указываем, через какое звуковое устройство нужно воспроизводить звук. Мы используем динамики, подключённые к USB-звуковой карте, которая имеет в системе индекс 2 — plughw:2.
Воспроизведение звука в ROS-нодах пакета soundplay_node построено не на привычных нам топиках (Topics) и сообщениях (Messages), а на клиент-серверных действиях (Actions). Подробнее читайте в ROS Wiki на страничке библиотеки actionlib.
Протестируем воспроизведение звука в ROS на Raspberry Pi. Запустим ноду soundplay_node свежесозданным launch-файлом:
source devel/setup.bash
roslaunch abot_text_to_speech abot_text_to_speech.launch
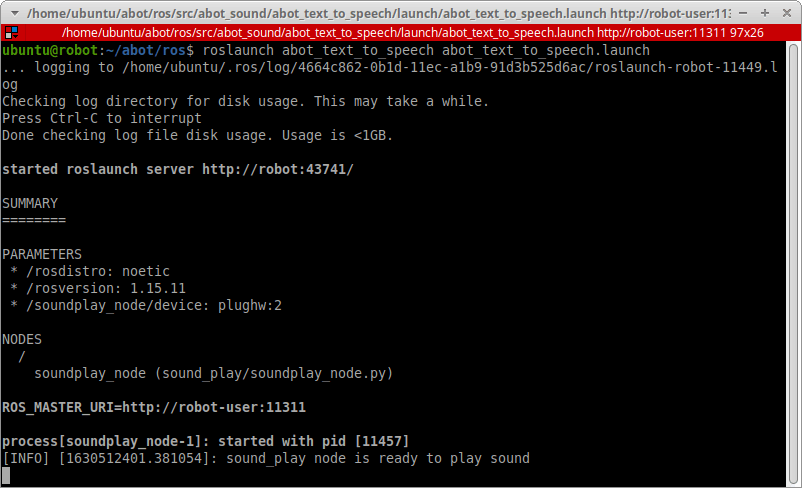
Чтобы было что воспроизводить, запишем любой звук через микрофон. В новом терминале воспользуемся командой arecord. Сохраним запись во временном файле /tmp/test-mic.wav.
arecord -f S16_LE -d 10 -r 16000 -c 1 -D plughw:1 /tmp/test-mic.wav
Отправим этот файл на воспроизведение в запущенную ноду soundplay_node:
source devel/setup.bash
rosrun sound_play play.py /tmp/test-mic.wav

Ваша запись должна заиграть через динамики.
Festival TTS
Начнём с нашей первой системы «Text-to-Speech» — Festival.
Установка и проверка
В ROS-пакете sound_play уже реализована программная обёртка для работы с Festival, но установить сам софт всё же нужно. Устанавиливаем Festival на Raspberry Pi из репозитория:
sudo apt-get install festival
Устанавливаем русскоязычную модель для Festival:
sudo apt-get install festvox-ru
Проверяем установку и запускаем Festival в терминале:
festival
Мы перейдём в консоль приложения. Выйти из консоли Festival можно сочетанием клавиш «CTRL+D», или набрав в терминале (quit).
В консоли Festival посмотрим все доступные языковые модели и голоса. Вводим:
(voice.list)

kal_diphone — это «захардкоженный» англоязычный голос. А вот mcu_ru_nsh_clunits — это уже мужской русский голос, единственный в TTS Festival. Меняем язык на русский командой:
(voice_msu_ru_nsh_clunits)
Язык сменится только на время работы в консоли Festival! Если вы хотите поменять его навсегда, придётся повозиться с настройками движка. Узнать, как настроить Festival, можно в статье на Wiki Arch Linux.
Произнесём какой-нибудь текст на русском и убедимся, что движок работает. Но какую фразу выбрать для проверки? Пусть нашей тестовой фразой будет самая известная русская панграмма, а за ней вставим какую-нибудь фразу с цифрами, например адрес Амперки:
Cъешь ещё этих мягких французских булок, да выпей чаю! Адрес Амперки: улица Тимура Фрунзе, дом 8 дробь 5, подъезд 1.
В терминале Festival вводим команду с тестовой фразой:
(SayText "Cъешь ещё этих мягких французских булок, да выпей чаю! Адрес Амперки: улица Тимура Фрунзе, дом 8 дробь 5, подъезд 1.")
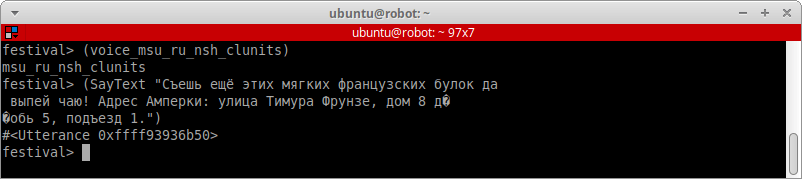
И слушаем звук с динамиков.
Качество так себе, да и возможный голос всего один. Но, тем не менее, все синтезированные слова нам понятны, движок работает и легко настраивается, так что мы можем его использовать.
Нода для Festival TTS
Напишем ROS-ноду — обёртку для движка Festival. Все ноды для TTS-движков будем писать на Python.
В пакете abot_text_to_speech в папке scripts создадим новый Pyhton-скрипт. Назовём его festvox_tts.py.
#!/usr/bin/env python
# coding: utf-8
import rospy
from std_msgs.msg import String, Bool
from sound_play.libsoundplay import SoundClient
class FestvoxTTS(object):
def __init__(self):
rospy.init_node('festvox_tts')
rospy.on_shutdown(self.shutdown)
self._volume = rospy.get_param('~volume', 1.0)
self._voice = rospy.get_param('~voice', 'voice_msu_ru_nsh_clunits')
self._soundhandle = SoundClient(blocking=True)
rospy.sleep(1)
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
rospy.loginfo("Festival TTS node: Start")
rospy.spin()
def processText(self, text_msg):
rospy.loginfo("Festival TTS node: Got a string: %s", text_msg.data)
self._pub.publish(True)
self._soundhandle.say(text_msg.data, self._voice, self._volume)
self._pub.publish(False)
@staticmethod
def shutdown():
rospy.loginfo("Festival TTS node: Stop")
rospy.sleep(1)
if __name__ == "__main__":
FestvoxTTS()
Как работает эта нода-обёртка?
Мы создали класс FestvoxTTS, экземпляр которого при инициализации cоздаст ROS-ноду festvox_tts.
class FestvoxTTS(object):
def __init__(self):
rospy.init_node('festvox_tts')
rospy.on_shutdown(self.shutdown)
При инициализации ноды создаём клиент SoundClient для воспроизведения звука нодой soundplay_node. Параметр blocking означает, что программа будет блокирована, пока аудиофайл или аудиоданные не проиграются полностью.
self._soundhandle = SoundClient(blocking=True)
С параметрического сервера ROS мы загрузим два параметра voice и volume. Параметром voice будем задавать имя голоса для использования в Festival, а параметром volume — громкость воспроизведения звука нодой soundplay_node.
self._volume = rospy.get_param('~volume', 1.0)
self._voice = rospy.get_param('~voice', 'voice_msu_ru_nsh_clunits')
Нода подписывается на топик /abot/tts/text_to_say, куда мы будем отправлять сообщения типа String с текстовыми строками, которые необходимо синтезировать в речь.
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
Это важно! Мы создали топик /abot/tts/speaking_in_progress с сообщениями типа Bool. Этот топик нужен, чтобы останавливать декодеры «Speech-to-Text». Когда мы скажем роботу голосовую команду, а он начнёт нам отвечать, сам звук его ответа не должен конфликтовать с режимами KWS и ASR. Когда робот говорит, ему не нужно слушать и распознавать свою собственную синтезированную речь.
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
Когда в топик /abot/tts/text_to_say поступает новая строка, мы останавливаем режимы «Speech-to-Text» и отправляем строку в Festival с указанием голоса и громкости. Функция say осуществляет обёртку движка Festival в ROS-ноде soundplay_node.
self._pub.publish(True)
self._soundhandle.say(text_msg.data, self._voice, self._volume)
self._pub.publish(False)
Запуск и тест ноды Festival TTS
В папке launch пакета abot_text_to_speech создадим файл запуска для новой ноды festvox_tts. Назовём его festvox_tts.launch.
<launch>
<arg name="volume" default="1.0" />
<arg name="voice" default="voice_msu_ru_nsh_clunits" />
<node name="festvox_tts" pkg="abot_text_to_speech" type="festvox_tts.py" output="screen" >
<param name="volume" value="$(arg volume)" />
<param name="voice" value="$(arg voice)" />
</node>
</launch>
В launch-файле указываем максимальную громкость звука — 1.0 и имя русского голоса для движка Festival — voice_msu_ru_nsh_clunits.
Включим новый файл запуска ноды festvox_tts в общий файл запуска для наших систем «Text to Speech» — abot_text_to_speech.launch:
<include file="$(find abot_text_to_speech)/launch/festvox_tts.launch" />
Запускаем на Raspberry Pi все TTS-ноды:
source devel/setup.bash
roslaunch abot_text_to_speech abot_text_to_speech.launch
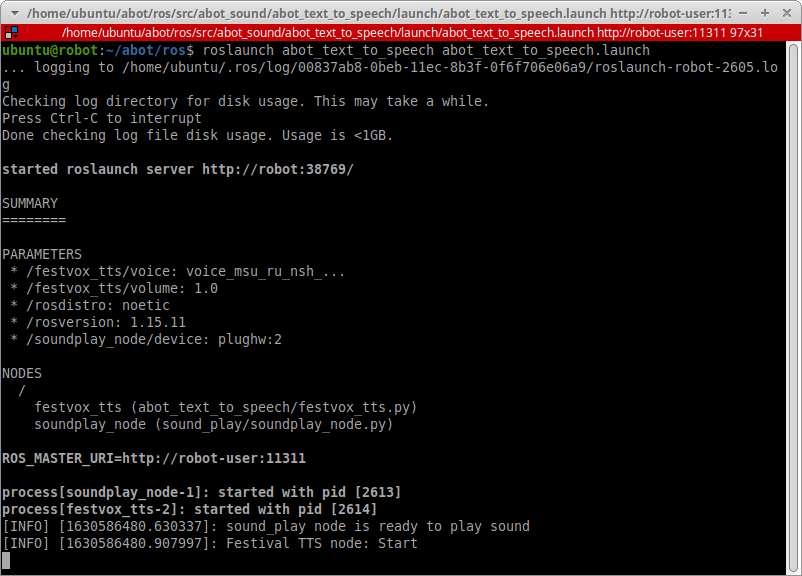
В новом терминале проверяем, появились ли новые топики /abot/tts/text_to_say и /abot/tts/speaking_in_progress.
rostopic list
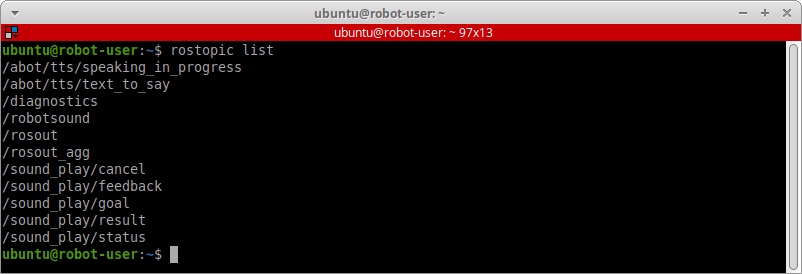
Пробуем отправить в топик /abot/tts/text_to_say какой-ниудь текст, например «Привет Амперка!», и послушаем синтезированный результат через динамики.
rostopic pub -1 /abot/tts/text_to_say std_msgs/String "Привет Амперка!"


Дерево нод и топиков сейчас выглядит так:

Рассмотрим другие системы «Text to Speech».
Amazon Polly
Следующая TTS-система на очереди — Amazon Polly, одна из самых известных в мире. Вы могли слышать синтезированные ей голоса много раз, например в смешных озвучках видео про роботов.
Как мы помним, Amazon Polly — это платный облачный сервис. Он предоставляется Amazon Web Services, или сокращённо AWS.
Это важно! Если вы никогда не пользовались AWS — не пугайтесь, никто сразу не заставит вас покупать какие-то решения или вбивать номер кредитки. Всем новым пользователям AWS бесплатно предоставляются 5 миллионов символов для синтезирования Amazon Polly в течение 12 месяцев. Этого более чем достаточно, чтобы вы протестили свои программы и поняли, нужна вам эта TTS-система или нет.
Установка и проверка Amazon Polly
Сперва вам нужно создать аккаунт Amazon Web Services. На сайте есть подробная инструкция, как начать работу с сервисами AWS.
Затем вам нужно войти в вашу консоль AWS и перейти в настройки вашего аккаунта. В настройках аккаунта нужно найти раздел «Your Security Credentials», в нём перейти в подраздел «Access keys (access key ID and secret access key)» и нажать на кнопку «Create new Access Key». Для вас будет сгенерирован секретный ключ Secret Access Key под определённым идентификатором Access Key ID. Сохраните эти ключи где-нибудь в надёжном месте.
Протестить сервис Amazon Polly очень легко. Просто перейдите на страничку сервиса или воспользуйтесь поиском в консоли AWS. У Amazon Polly TTS есть два типа движков — Standart и Neural. Движок Neural построен на гигантских нейросетях и синтезирует речь, неотличимую от человеческой. Для русского языка в Amazon Polly доступен только стандартный движок и всего два голоса: женский — Tatyana и мужской — Maxim.
Прогоним нашу тестовую фразу женским голосом:
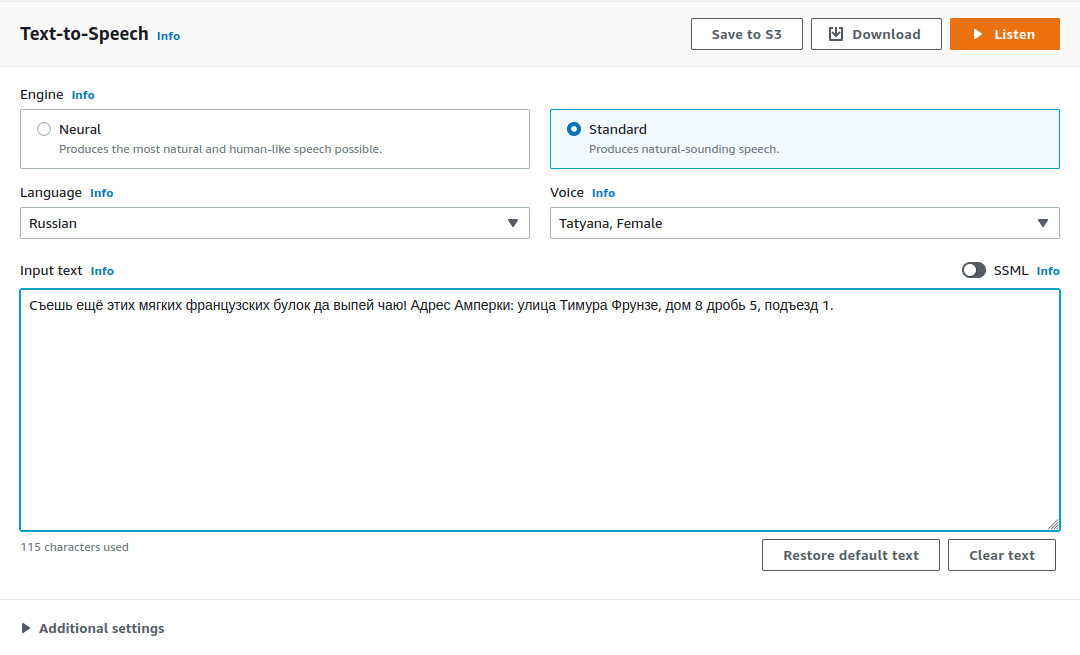
Вот какой получился результат:
Звучит гораздо лучше, чем Festival. На то он и платный сервис.
Также Amazon Polly поддерживает язык разметки синтеза речи, или SSML. Используя специальные теги в вашем тексте, вы можете настроить индивидуальное произношение слов, расставить правильные ударения в словах, добавить эмоциональный окрас в предложениях, например крик или шепот.
Для работы с сервисом AWS на Raspberry Pi установим официальный Python-пакет Boto3 от Amazon:
sudo apt-get install python3-pip
pip install boto3
Нода для Amazon Polly TTS
Напишем ROS-ноду — обёртку для Amazon Polly.
В пакете abot_text_to_speech в папке scripts создадим новый Pyhton-скрипт. Назовём его aws_polly_tts.py.
#!/usr/bin/env python
# coding: utf-8
import rospy
from boto3 import Session
from std_msgs.msg import String, Bool
from sound_play.libsoundplay import SoundClient
class AWSPollyTTS(object):
def __init__(self):
rospy.init_node('aws_polly_tts')
rospy.on_shutdown(self.shutdown)
self._volume = rospy.get_param('~volume', 1.0)
self._aws_speech_sound_file_path = rospy.get_param('~aws_speech_sound_file_path')
self._aws_access_key_id = rospy.get_param('~aws_access_key_id')
self._aws_secret_access_key = rospy.get_param('~aws_secret_access_key')
self._aws_region_name =rospy.get_param('~aws_region_name', 'us-west-2')
self._aws_polly_voice_id =rospy.get_param('~aws_polly_voice_id')
self._session = Session(aws_access_key_id=self._aws_access_key_id, aws_secret_access_key=self._aws_secret_access_key, region_name=self._aws_region_name)
self._polly = self._session.client('polly')
self._soundhandle = SoundClient(blocking=True)
rospy.sleep(1)
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
rospy.loginfo("AWS Polly TTS node: Start")
rospy.spin()
def processText(self, text_msg):
rospy.loginfo("AWS Polly TTS node: Got a string: %s", text_msg.data)
response = self._polly.synthesize_speech(VoiceId=self._aws_polly_voice_id, OutputFormat='ogg_vorbis', Text = text_msg.data)
rospy.loginfo("AWS Polly TTS node: Saving speech to file: %s", self._aws_speech_sound_file_path)
file = open(self._aws_speech_sound_file_path, 'wb')
file.write(response['AudioStream'].read())
file.close()
self._pub.publish(True)
rospy.loginfo('AWS Polly TTS node: Playing "%s".', self._aws_speech_sound_file_path)
self._soundhandle.playWave(self._aws_speech_sound_file_path, self._volume)
self._pub.publish(False)
@staticmethod
def shutdown():
rospy.loginfo("AWS Polly TTS node: Stop")
rospy.sleep(1)
if __name__ == "__main__":
AWSPollyTTS()
Как работает эта нода?
Мы создали класс AWSPollyTTS, экземпляр которого при инициализации cоздаст ROS-ноду aws_polly_tts.
class AWSPollyTTS(object):
def __init__(self):
rospy.init_node('aws_polly_tts')
rospy.on_shutdown(self.shutdown)
С параметрического сервера ROS мы загрузим следующие параметры:
aws_access_key_id— ID секретного ключа AWS.aws_secret_access_key— сам секретный ключ AWS.aws_region_name— регион работы AWS.aws_polly_voice_id— голос, который хотим использовать в Amazon Polly.aws_speech_sound_file_path— абсолютный путь в файловой системе, куда сохранить аудиозапись, полученную от сервера.volume— громкость воспроизведения звука нодойsoundplay_node.
self._volume = rospy.get_param('~volume', 1.0)
self._aws_speech_sound_file_path = rospy.get_param('~aws_speech_sound_file_path')
self._aws_access_key_id = rospy.get_param('~aws_access_key_id')
self._aws_secret_access_key = rospy.get_param('~aws_secret_access_key')
self._aws_region_name =rospy.get_param('~aws_region_name', 'us-west-2')
self._aws_polly_voice_id =rospy.get_param('~aws_polly_voice_id')
Нода подписывается на топик /abot/tts/text_to_say, куда мы отправляем сообщения типа String с текстовыми строками, которые необходимо синтезировать в речь. Также публикуем сообщения Bool в топик /abot/tts/speaking_in_progress для остановки декодеров «Speech-to-Text».
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
При инициализации ноды создаём клиент SoundClient для воспроизведения звука нодой soundplay_node. Параметр blocking означает, что программа будет блокирована, пока аудиофайл или аудиоданные не проиграются полностью.
self._soundhandle = SoundClient(blocking=True)
Запускаем новую сессию с сервисом AWS c указанием секретного ключа, ID ключа и региона. Создаём обьект polly — клиент сервиса Amazon Polly.
self._session = Session(aws_access_key_id=self._aws_access_key_id, aws_secret_access_key=self._aws_secret_access_key, region_name=self._aws_region_name)
self._polly = self._session.client('polly')
Когда в топик /abot/tts/text_to_say поступает новая строка, мы отправляем запрос с этой строкой на сервер Amazon. В запросе указываем ID голоса, который хотим использовать для синтезатора, и формат аудиоданных, который хотим иметь на выходе. Используем только формат OGG, так как нода soundplay_node не умеет воспроизводить сжатые аудиоданные в формате MP3.
response = self._polly.synthesize_speech(VoiceId=self._aws_polly_voice_id, OutputFormat='ogg_vorbis', Text = text_msg.data)
Полученные с сервера аудиоданные сохраняем в файл:
file = open(self._aws_speech_sound_file_path, 'wb')
file.write(response['AudioStream'].read())
file.close()
А затем отправляем этот файл на воспроизведение через клиент ноды soundplay_node, остановив при этом декодеры «Speech-to-Text».
self._pub.publish(True)
self._soundhandle.playWave(self._aws_speech_sound_file_path, self._volume)
self._pub.publish(False)
Запуск и тест ноды Amazon Polly
В папке launch пакета abot_text_to_speech создадим файл запуска для новой ноды aws_polly_tts. Назовём его aws_polly_tts.launch.
<launch>
<arg name="volume" default="1.0" />
<arg name="aws_speech_sound_file_path" default="$(find abot_text_to_speech)/sounds/aws_polly/speech.ogg" />
<arg name="aws_access_key_id" default="PUT YOUR AWS ACCESS KEY ID HERE!" />
<arg name="aws_secret_access_key" default="PUT YOUR AWS SECRET ACCESS KEY HERE!" />
<arg name="aws_region_name" default="us-west-2" />
<arg name="aws_polly_voice_id" default="Tatyana" />
<node name="aws_polly_tts" pkg="abot_text_to_speech" type="aws_polly_tts.py" output="screen" >
<param name="volume" value="$(arg volume)" />
<param name="aws_speech_sound_file_path" value="$(arg aws_speech_sound_file_path)" />
<param name="aws_access_key_id" value="$(arg aws_access_key_id)" />
<param name="aws_secret_access_key" value="$(arg aws_secret_access_key)" />
<param name="aws_region_name" value="$(arg aws_region_name)" />
<param name="aws_polly_voice_id" value="$(arg aws_polly_voice_id)" />
</node>
</launch>
Через launch-файл задаём параметры для параметрического сервера ROS:
volumeи1.0— указываем максимальную громкость воспроизведения звука.aws_access_key_id— здесь указываем ID нашего секретного ключа AWS.aws_secret_access_key— указываем, собственно, сам ключ от сервисов AWS.aws_region_name— для России стандартным регионом являетсяus-west-2.aws_polly_voice_id— голос для движка. Пусть робот говорит женским голосом, для этого задаём IDTatyana.aws_speech_sound_file_path— путь, куда сохранить полученные аудиоданные. Будем сохранять ответы с сервера в OGG-файлspeech.ogg. Сам файл будем хранить в папкеsounds/aws_pollyпакетаabot_text_to_speech.
Включим новый файл запуска ноды aws_polly_tts в общий файл запуска для наших систем «Text to Speech» — abot_text_to_speech.launch, при этом закомментируем предыдущую TTS-систему Festival, чтобы они не конфликтовали.
<!-- <include file="$(find abot_text_to_speech)/launch/festvox_tts.launch" /> -->
<include file="$(find abot_text_to_speech)/launch/aws_polly_tts.launch" />
Запускаем на Raspberry Pi все ноды «Text to Speech»:
source devel/setup.bash
roslaunch abot_text_to_speech abot_text_to_speech.launch
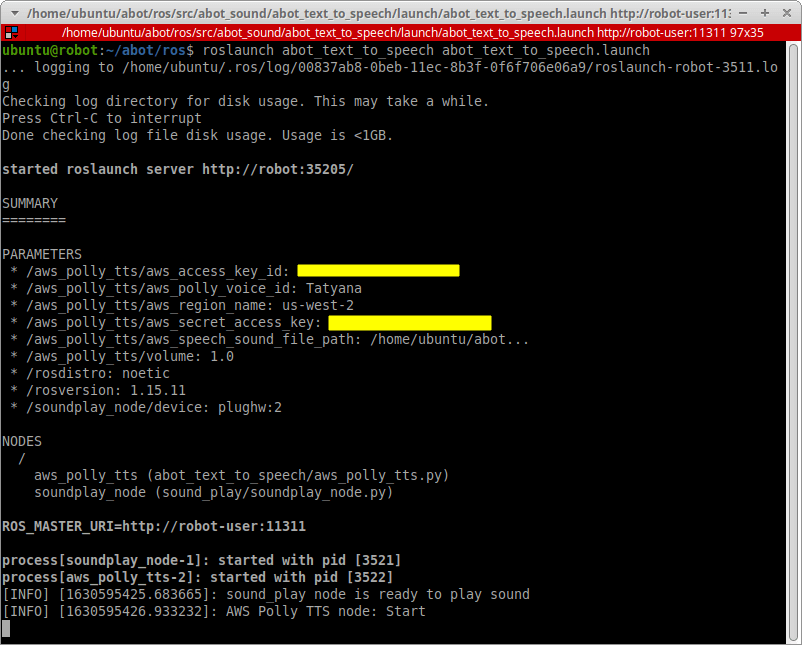
В новом терминале проверяем, появились ли новые топики /abot/tts/text_to_say и /abot/tts/speaking_in_progress.
rostopic list
Затем пробуем отправить в топик /abot/tts/text_to_say тестовый текст «Привет Амперка!» и послушать синтезированный результат уже через динамики.
rostopic pub -1 /abot/tts/text_to_say std_msgs/String "Привет Амперка!"
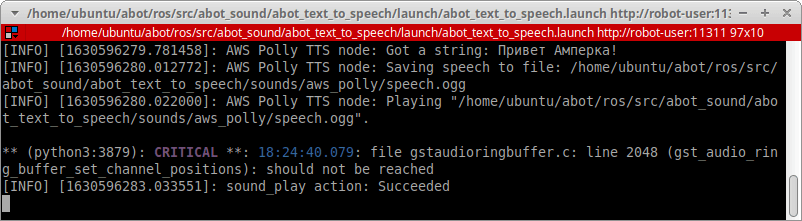
Дерево нод и топиков в этом случае выглядит так:

Рассмотрим ещё одну TTS-систему.
RHVoice TTS
Мы протестировали уже две системы «Text to Speech». Однако у синтезированной через систему Festival речи довольно низкое качество. Речь, синтезированная через Amazon Polly — качественная, но для нас этот сервис уже полностью платный, так как нашему AWS-аккаунту уже больше нескольких лет. Хочется найти бесплатное решение, работающее оффлайн.
В результате мы остановились на бесплатной TTS-системе RHVoice, которая на наш взгляд, довольно качественно синтезирует речь. Кроме этого данная система создана российскими разработчиками и изначально нацелена именно на русский язык.
Установка и проверка
Устанавливаем RHVoice, используя готовый пакет из их репозитория. Для arm64 есть готовый пакет, так что на Raspberry Pi всё ставится без проблем.
sudo add-apt-repository ppa:linvinus/rhvoice
sudo apt-get update
sudo apt-get install rhvoice
Из коробки над доступны несколько голосов, в том числе четыре русских: Aleksandr, Anna, Elena, Irina.
При установке RHVoice пакетом из репозитория можно проверить установку системы через терминал командой RHVoice-client. Прогоним систему на нашей тестовой фразе. Синтезируем речь, используя женский голос Anna. В команде не забываем указывать индекс звукового устройства для вывода звука — aplay -D plughw:2.
echo "Cъешь ещё этих мягких французских булок да выпей чаю! Адрес Амперки: улица Тимура Фрунзе, дом 8 дробь 5, подъезд 1." | RHVoice-client -s Anna+CLB | aplay -D plughw:2

Послушаем результат:
Чтобы сохранить синтезированную речь в файл, RHVoice рекомендует использовать аудиоредактор Sound eXchange, или просто sox. Устновим его на нашу Raspberry Pi:
sudo apt-get install sox
Теперь мы можем сохранить синтезированную речь в файл. Например, для сохранения синтезированной фразы «Привет Амперка!» во временный файл /tmp/test.wav команда будет выглядить так:
echo "Привет Амперка!" | RHVoice-client -s Anna+CLB | sox -t wav - -r 24000 -c 1 -b 16 -t wav - >/tmp/test.wav
В контейнер WAV будет записан одноканальный 16-битный звук с частотой дискретизации 24 кГц.
Эта TTS-система нам очень понравилась, и мы решили использовать в данном проекте имеено её. Тем не менее, мы также оставили исходные файлы для других систем. Вдруг они вам пригодятся.
Нода для RHVoice TTS
Напишем ROS-ноду — обёртку для RHVoice TTS.
Мы не будем использовать никакие сторонние библиотеки для обёртки системы RHVoice. Просто сделаем так, чтобы ROS-нода на Python внутри себя запускала процесс другой программы, а именно RHVoice-client. В этой ноде будем запускать RHVoice-client точно таким же образом, как мы это делали через терминал.
В пакете abot_text_to_speech в папке scripts создадим новый Pyhton-скрипт. Назовём его rhvoice_tts.py.
#!/usr/bin/env python
# coding: utf-8
import rospy
import subprocess
from std_msgs.msg import String, Bool
from sound_play.libsoundplay import SoundClient
class RHVoiceTTS(object):
def __init__(self):
rospy.init_node('rhvoice_tts')
rospy.on_shutdown(self.shutdown)
self._volume = rospy.get_param('~volume', 1.0)
self._rhvoice_speech_sound_file_path = rospy.get_param('~rhvoice_speech_sound_file_path')
self._rhvoice_voice = rospy.get_param('~rhvoice_voice', 'Anna+CLB')
self._soundhandle = SoundClient(blocking=True)
rospy.sleep(1)
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
rospy.loginfo("RHVoice TTS node: Start")
rospy.spin()
def processText(self, text_msg):
rospy.loginfo("RHVoice TTS node: Got a string: %s", text_msg.data)
rospy.loginfo("RHVoice TTS node: Saving speech to file: %s", self._rhvoice_speech_sound_file_path)
rhvoice_command_line = "echo '" + text_msg.data + "' | RHVoice-client -s " + self._rhvoice_voice + " "
rhvoice_command_line += "| sox -t wav - -r 24000 -c 1 -b 16 -t wav - >" + self._rhvoice_speech_sound_file_path
rospy.loginfo("RHVoice TTS node: Command: %s", rhvoice_command_line)
subprocess.call(rhvoice_command_line, shell=False)
self._pub.publish(True)
rospy.loginfo('RHVoice TTS node: Playing "%s".', self._rhvoice_speech_sound_file_path)
self._soundhandle.playWave(self._rhvoice_speech_sound_file_path, self._volume)
self._pub.publish(False)
rospy.loginfo('RHVoice TTS node: Stop Playing')
@staticmethod
def shutdown():
rospy.loginfo("RHVoice TTS node: Stop")
rospy.sleep(1)
if __name__ == "__main__":
RHVoiceTTS()
Как работает эта нода?
Мы создали класс RHVoiceTTS, экземпляр которого при инициализации cоздаст ROS-ноду rhvoice_tts.
class RHVoiceTTS(object):
def __init__(self):
rospy.init_node('rhvoice_tts')
rospy.on_shutdown(self.shutdown)
С параметрического сервера ROS мы загрузим следующие параметры:
rhvoice_voice— ID голоса, который хотим использовать для синтеза в RHVoice.rhvoice_speech_sound_file_path— абсолютный путь в файловой системе, куда сохранится созданнаяsoxаудиозапись.volume— громкость воспроизведения звука нодойsoundplay_node.
self._volume = rospy.get_param('~volume', 1.0)
self._rhvoice_speech_sound_file_path = rospy.get_param('~rhvoice_speech_sound_file_path')
self._rhvoice_voice = rospy.get_param('~rhvoice_voice', 'Anna+CLB')
Нода подписывается на топик /abot/tts/text_to_say. В этот топик мы отправляем сообщения типа String с текстовыми строками, которые необходимо синтезировать в речь. Также публикуем сообщения Bool в топик /abot/tts/speaking_in_progress для остановки декодеров «Speech-to-Text».
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
При инициализации ноды создаём клиент SoundClient для воспроизведения звука нодой soundplay_node. Параметр blocking означает, что программа будет блокирована, пока аудиофайл или аудиоданные не проиграются полностью.
self._soundhandle = SoundClient(blocking=True)
Когда в топик /abot/tts/text_to_say поступает новая строка, мы берем эту строку, путь для сохранения звукового файла, выбранный голос диктора и формируем команду для запуска программы RHVoice-client. Готовая команда выглядит так же, как если бы мы вводили её в терминал. Сформированную команду запускаем в отдельном подпроцессе.
rhvoice_command_line = "echo '" + text_msg.data + "' | RHVoice-client -s " + self._rhvoice_voice + " "
rhvoice_command_line += "| sox -t wav - -r 24000 -c 1 -b 16 -t wav - >" + self._rhvoice_speech_sound_file_path
subprocess.call(rhvoice_command_line, shell=False)
Когда подпросесс с программой RHVoice-client закончит свою работу, у нас будет готовый аудиофайл. Отправляем этот файл на воспроизведение через клиент ноды soundplay_node, остановив при этом декодеры «Speech-to-Text».
self._pub.publish(True)
self._soundhandle.playWave(self._rhvoice_speech_sound_file_path, self._volume)
self._pub.publish(False)
Запуск и тест ноды RHVoice
В папке launch пакета abot_text_to_speech создадим файл запуска для новой ноды rhvoice_tts. Назовём его rhvoice_tts.launch.
<launch>
<arg name="volume" default="1.0" />
<arg name="rhvoice_speech_sound_file_path" default="$(find abot_text_to_speech)/sounds/rhvoice/speech.wav" />
<arg name="rhvoice_voice" default="Anna+Clb" />
<node name="rhvoice_tts" pkg="abot_text_to_speech" type="rhvoice_tts.py" output="screen" >
<param name="volume" value="$(arg volume)" />
<param name="rhvoice_speech_sound_file_path" value="$(arg rhvoice_speech_sound_file_path)" />
<param name="rhvoice_voice" value="$(arg rhvoice_voice)" />
</node>
</launch>
Через launch-файл задаём параметры для параметрического сервера ROS:
volumeи1.0— указываем максимальную громкость воспроизведения звука.rhvoice_speech_sound_file_path— путь, куда сохранить созданныйsoxаудиофайл. Будем сохранять синтезированую речь в WAV-файлspeech.wav. Сам файл будем хранить в папке/sounds/rhvoice/пакетаabot_text_to_speech.rhvoice_voice— выбранный голос для движка RHVoice. Голос задаётся комбинацией из двух голосов. Первый голос — основной, который озвучивает весь текст. Если первым голосом не получается произнести какие-то фонемы или фрагменты речи, то используется второй вспомогательный голос, и все они англоязычные. В нашем пакете их три:alan(муж.),clb(жен.) иslt(жен.). Голоса записываются через символ+. Например, итоговые голоса могут бытьAleksandr+Alan,Anna+Clb,Elena+stl,Irina+stl. Мы используем комбинацию голосовAnna+Clb.
Включим новый файл запуска ноды rhvoice_tts в общий файл запуска для наших систем «Text to Speech» — abot_text_to_speech.launch, при этом закомментируем предыдущие TTS-системы Festival и Amazon Polly, чтобы избежать конфликтов.
<!-- <include file="$(find abot_text_to_speech)/launch/festvox_tts.launch" /> -->
<!-- <include file="$(find abot_text_to_speech)/launch/aws_polly_tts.launch" /> -->
<include file="$(find abot_text_to_speech)/launch/rhvoice_tts.launch" />
Запускаем на Raspberry Pi все наши ноды «Text to Speech»:
source devel/setup.bash
roslaunch abot_text_to_speech abot_text_to_speech.launch
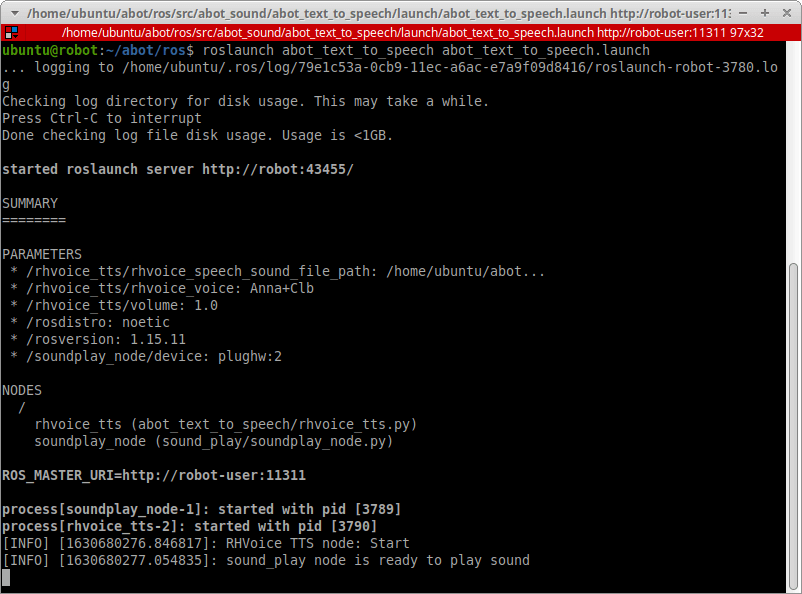
В новом терминале проверяем, появились ли новые топики /abot/tts/text_to_say и /abot/tts/speaking_in_progress.
rostopic list
Затем пробуем отправить в топик /abot/tts/text_to_say тестовый текст «Привет, Амперка!» и послушать синтезированный результат через динамики.
rostopic pub -1 /abot/tts/text_to_say std_msgs/String "Привет Амперка!"
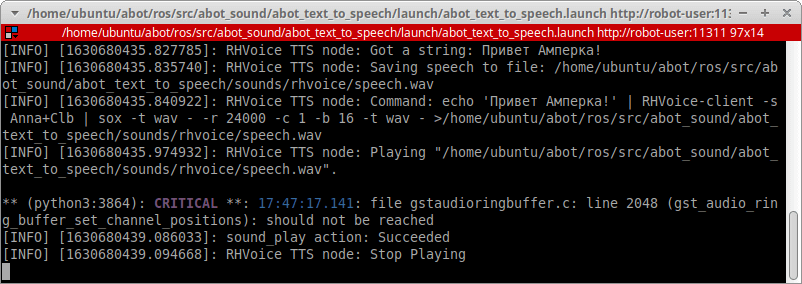
Дерево нод и топиков в этом случае выглядит так:

Правки в KWS
Внесём несколько финальных правок в KWS-скрипт.
Наши ноды «Text to Speech» сейчас используют топик /abot/tts/speaking_in_progress, чтобы сообщать, воспроизводится ли аудио или нет.
Это важный момент. Когда робот воспроизводит синтезированную речь, её не нужно распознавать системой «Speech-to-Text». То есть, пока проигрывается аудио, нам нужно поставить KWS-декодер на паузу.
Для этого в ноде kws_script.py мы подпишемся на топик /abot/tts/speaking_in_progress и создадим простой флажок _tts_is_speaking.
self._tts_is_speaking = bool.data
rospy.Subscriber("/abot/tts/speaking_in_progress", Bool, self.ttsSpeakingCheck)
Каждый раз, когда в топике /abot/tts/speaking_in_progress обновляются данные, мы меняем состояние флага.
def ttsSpeakingCheck(self, bool_msg):
self._tts_is_speaking = bool_msg.data
if self._tts_is_speaking:
rospy.loginfo("KWS control node: Decoder paused while TTS is speaking")
else:
rospy.loginfo("KWS control node: Decoder returned to work")
Обработку аудиобуфера с микрофона выполняем, только если процесс проигрывания аудио с динамиков завершился:
def processAudio(self, audio_buffer):
self._decoder.process_raw(audio_buffer, False, False)
if self._tts_is_speaking is False:
if self._decoder.hyp() is not None:
for seg in self._decoder.seg():
rospy.logwarn("Detected key words: %s ", seg.word)
self._decoder.end_utt()
msg = seg.word
self._kws_data_pub.publish(msg)
self._kws_found = True
self._decoder.start_utt()
if self._kws_found == True:
msg = AudioData()
msg.data = audio_buffer
self._grammar_audio_pub.publish(msg)
Голосовое управление роботом
Отлично, наши системы «Speech-to-Text» и «Text to Speech» работают, и у нас готовы все необходимые ROS-ноды.
Пришло время реализовать голосовое управление в реальном роботе Abot.
Напоминаем, что все исходные файлы нашего робо-проекта можно посмотреть в GitHub-репозитории Abot.
Придумываем голосовые команды
Ключевое слово для режима KWS движка PocketSphinx мы оставили прежнее — «Робот».
Мы начали с простых задач и продолжили более сложными. Для примера мы придумали и реализовали три полезных способа применения голосового управления.
Мы можем узнать у робота время и дату. Очень полезно, если под рукой нет часов и не хочется лезть в телефон.
Запрос роботу для уточнения времени:
- «Робот, который час?»
- «Робот, сколько времени?»
Ответ робота:
- Например, «Время — двадцать три часа пятьдесят восемь минут».
Запрос роботу для уточнения даты:
- «Робот, текущая дата?»
- «Робот, сегодняшнее число?»
Ответ робота:
- Например, «Дата — шестнадцатое февраля, понедельник».
Наш робот ездит на аккумуляторах, и не всегда удобно следить за уровнем их заряда. Мы можем узнать у робота уровень заряда его батареи: просто спросим голосом — и он нам ответит. Используем две команды: одной узнаём, сколько процентов заряда осталось, а второй ещё и узнаём напряжение.
Запрос роботу для уровня заряда батареи:
- «Робот, заряд батареи?»
- «Робот, заряд аккумулятора?»
Ответ робота:
- Например, «Заряд — восемьдесят четыре процента».
Запрос роботу для уровня заряда и напряжения батареи:
- «Робот, заряд батареи, подробно?»
- «Робот, заряд аккумулятора, подробно?»
Ответ робота:
- Например, «Заряд — девяносто девять процентов. Напряжение — 8,4 вольта».
Мы интегрировали голосовое управление в систему навигации робота.
Голосом мы можем задавать роботу навигационные цели на карте. Наш робот обитает в офисе. В качестве навигационной цели мы задали место, где сидит определённый человек, или исходное место робота.
Запросы роботу:
- «Робот, едь к Виктору».
- «Робот, едь к Михаилу».
- «Робот, едь к Антону».
- «Робот, едь домой».
Ответ робота:
- Например: «Еду к Антону». Робот прокладывает путь до точки на карте, где сидит Антон, и начинает движение по маршруту.
Ещё мы можем осуществить голосовое управление простыми движениями робота.
Запросы роботу:
- «Робот, разворот». (Вращение платформы на π рад влево)
- «Робот, поворот влево». (Вращение платформы на π/2 рад влево)
- «Робот, поворот вправо». (Вращение платформы на π/2 рад вправо)
- «Робот, движение вперёд на метр».
- «Робот, движение вперёд на полметра».
- «Робот, движение назад на метр».
- «Робот, движение назад на полметра».
Ответ робота:
- «Выполняю». Робот выполняет указанное перемещение.
Эти движения робота тоже выполняются навигационным стеком ROS.
Сперва мы перенастраиваем систему «Speech-to-Text» на изменённые голосовые команды. Новые настройки мы разместили в папке config пакета abot_speech_to_text. Делаем всё по тому же принципу, как в примере с двумя светодиодами.
Лист ключевых слов abot_kwslist.kwslist содержит единственное слово «Робот» с порогом 1e-5.
робот /1e-5/
Словарь робота abot_dictionary.txt содержит 30 слов. Фонетический словарь abot_dictionary.dic, сгенерированный скриптом text2dict из пакета ru4sphinx, выглядит следующим образом:
аккумулятора a k u m u ll ja t ay r ay
антону a n t oo n u
батареи b ay t a rr je i
виктору vv i k t oo r u
влево v ll je v ay
вперёд f pp i rr jo t
вправо f p r aa v ay
времени v rr je mm i nn i
времени(2) v rr i mm i nn ii
дата d aa t ay
движение d vv i zh ee nn i i
домой d a m oo j
едь j i tt
заряд z a rr ja t
к k y
к(2) k ee
к(3) k
к(4) h
который k a t oo r y j
метр mm je t r
метра mm je t r ay
михаилу mm i h a ii l u
на n aa
назад n a z aa t
поворот p ay v a r oo t
подробно p a d r oo b n ay
пол p oo l
разворот r ay z v a r oo t
робот r oo b ay t
сегодняшнее ss i g oo d nn i sh nn i i
сколько s k oo ll k ay
текущая tt i k uu sch i i
час ch ja s
число ch i s l oo
А так выглядит описание формальной грамматики робота abot_gram.gram:
#JSGF V1.0;
grammar robot_cmd;
public <all_commands> = <state> | <command> ;
<state> = <state_1> | <state_2> | <state_3> ;
<state_1> = сколько времени | который час ;
<state_2> = текущая дата | сегодняшнее число ;
<state_3> = заряд ( батареи | аккумулятора ) [ подробно ] ;
<command> = <command_1> | <command_2> | <command_3> | <command_4> | <command_5> ;
<command_1> = едь ( к виктору | к михаилу | к антону | домой ) ;
<command_2> = разворот ;
<command_3> = поворот влево | поворот вправо ;
<command_4> = движение вперёд на ( метр | пол метра );
<command_5> = движение назад на ( метр | пол метра );
В файле запуска abot_speech_to_text.launch нашей системы «Speech-to-Text» указываем пути до новых файлов настройки:
<arg name="hmm" default="$(find abot_speech_to_text)/model/zero_ru_cont_8k_v3/zero_ru.cd_cont_4000" />
<arg name="dict" default= "$(find abot_speech_to_text)/config/abot_dictionary.dic" />
<arg name="kws" default="$(find abot_speech_to_text)/config/abot_kwslist.kwslist" />
<arg name="gram" default="$(find abot_speech_to_text)/config/abot_gram" />
<arg name="grammar" default="robot_cmd" />
<arg name="rule" default="all_commands" />
Крепление для звуковых устройств
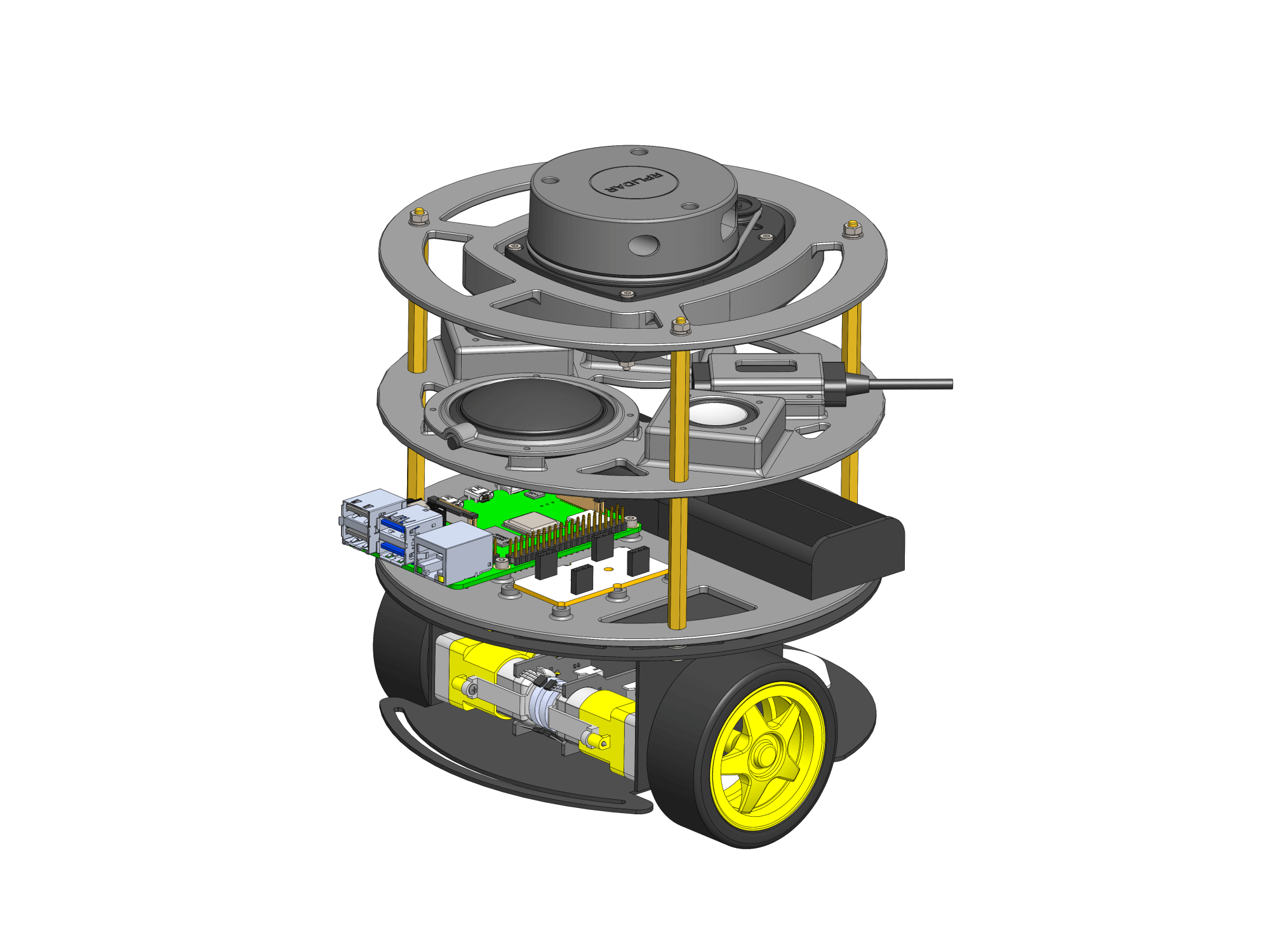
В данный момент микрофон и динамики подключены к Raspberry Pi без какого-либо крепежа — они просто лежат на столе рядом с платой. Но наш робот Abot — мобильный, так что мы не можем оставить висящие провода и болтающийся микрофон. Для звуковых устройств нужно сделать специальное крепление, чтобы они стали неотъемлемой частью робота.
Как и прежде, мы напечатаем крепления для звуковых устройств на 3D-принтере. Главная деталь крепления звука сделана в виде панели или диска, по аналогии c креплением Raspberry Pi и креплением лидара. Деталь напечатали на Prusa i3 MK3S из серого PLA-пластика eSUN.

Динамики VECO 32KC08-1 и Troyka-усилитель класса D имеют удобные монтажные отверстия. Динамики — под винт M2, Troyka-усилитель — под винт М3. С их креплением проблем нет. А вот на звуковой карте и микрофоне крепёжные отверстия отсутствуют. Для крепления этих компонентов мы напечатали две прижимные пластины под крепёж М2:

Мы закрепили все звуковые устройства на 3D-напечатанной панели:

Подключаем звуковые устройства к Raspberry Pi:

А саму звуковую панель размещаем между панелью крепления RPi и панелью лидара через стойки М3×50:

Обновление URDF-описания и карты
Мы должны задокументировать все новые детали как в 3D-модели робота, так и в URDF-описании. Данное обновление в конструкции робота — отличный пример, что регистрировать изменения стоит обязательно, и вот почему.
Мы установили напечатанную панель со звуковыми устройствами между панелью Raspberry Pi и панелью лидара. Мы поместили её именно в это место для сохранения круговой области действия лидара. Положение лидара стало на 53 мм выше, чем было (высота стойки плюс толщина напечатанной панели). Лидар — это 2D-сенсор, и работает он в плоскости. Теперь плоскость действия лидара стала выше от земли, и мы не можем использовать нашу сохранённую карту в навигации. Ведь та карта была построена на информации с лидара, который стоял ниже. Если мы запустим привычную навигацию по сохранённой карте, робот не сможет локализироваться, ведь теперь он всё видит иначе — выше на 5,3 см. На карте там, где не было преград, могут появиться новые, а там, где они были — могут пропасть.
Обновляем 3D-модель робота в SolidWorks:
Используя плагин solidworks_urdf_exporter, производим экспорт 3D-модели в URDF описание:

Cтроим новую карту методом SLAM, используя геймпад DualShock 4:

Узнаём у робота дату и время
Нода обработчика
В папке src пакета abot_speech_command создаем новую ROS-ноду для обработки наших «временны́х» голосовых команд. Ноду пишем на С++, назовём её vc_get_system_time.
Заголовочный файл vc_get_system_time.h с классом VCGetSystemTime:
#ifndef VC_GET_SYSTEM_TIME_H_
#define VC_GET_SYSTEM_TIME_H_
#include <ros/ros.h>
#include <std_msgs/String.h>
#include <string>
#include <vector>
#include <time.h>
const std::vector<std::string> VOICE_COMMANDS_GET_SYSTEM_TIME = {
"который час",
"сколько времени",
"текущая дата",
"сегодняшнее число"
};
const std::vector<std::string> DAY_STRINGS = {
"первое", "второе", "третье", "четвёртое",
"пятое", "шестое", "седьмое", "восьмое",
"девятое", "десятое", "одиннадцатое", "двенадцатое",
"тринадцатое", "четырнадцатое", "пятнадцатое", "шестнадцатое",
"семнадцатое", "восемнадцатое", "девятнадцатое", "двадцатое",
"двадцать первое", "двадцать второе", "двадцать третье",
"двадацать четвёртое", "двадцать пятое", "двадцать шестое",
"двадцать седьмое", "двадцать восьмое", "двадцать девятое",
"тридцатое", "тридцать первое"
};
const std::vector<std::string> MONTH_STRINGS = {
"января", "февраля", "марта", "апреля",
"мая", "июня", "июля", "августа",
"сентября", "октября", "ноября", "декабря"
};
const std::vector<std::string> DAY_OF_A_WEEK_STRINGS = {
"понедельник", "вторник", "среда", "четверг",
"пятница", "суббота", "воскресенье"
};
class VCGetSystemTime {
public:
VCGetSystemTime();
private:
ros::NodeHandle _node;
ros::Subscriber _stt_sub;
ros::Publisher _tts_pub;
time_t _rawtime;
struct tm* _timeinfo;
void getTimeInfo();
std::string makeTimeString();
std::string makeDateString();
void grammarCallback(const std_msgs::String::ConstPtr& msg);
};
VCGetSystemTime::VCGetSystemTime() {
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetSystemTime::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
}
void VCGetSystemTime::grammarCallback(const std_msgs::String::ConstPtr& msg) {
std::string grammar_string = msg->data.c_str();
if (grammar_string == VOICE_COMMANDS_GET_SYSTEM_TIME[0] || grammar_string == VOICE_COMMANDS_GET_SYSTEM_TIME[1]) {
getTimeInfo();
std_msgs::String tts_string_msg;
tts_string_msg.data = makeTimeString();
_tts_pub.publish(tts_string_msg);
}
if (grammar_string == VOICE_COMMANDS_GET_SYSTEM_TIME[2] || grammar_string == VOICE_COMMANDS_GET_SYSTEM_TIME[3]) {
getTimeInfo();
std_msgs::String tts_string_msg;
tts_string_msg.data = makeDateString();
_tts_pub.publish(tts_string_msg);
}
}
void VCGetSystemTime::getTimeInfo() {
time(&_rawtime);
_timeinfo = localtime(&_rawtime);
}
std::string VCGetSystemTime::makeTimeString() {
int hours = (_timeinfo->tm_hour) % 24;
int minutes = _timeinfo->tm_min;
std::string hours_word_string;
std::string hours_string = std::to_string(hours);
if (hours == 1 || hours == 21)
hours_word_string = " час ";
else if ((hours >= 2 && hours <= 4) || hours == 22 || hours == 23)
hours_word_string = " часа ";
else
hours_word_string = " часов ";
int minutes_second_digit = minutes / 10;
int minutes_fisrt_digit = minutes % 10;
std::string minutes_string;
if (minutes == 1)
minutes_string = "одна";
else if (minutes_fisrt_digit == 1 && minutes_second_digit != 1)
minutes_string = std::to_string(minutes - 1) + " одна";
else if (minutes == 2)
minutes_string = "две";
else if (minutes_fisrt_digit == 2 && minutes_second_digit != 1)
minutes_string = std::to_string(minutes - 2) + " две";
else
minutes_string = std::to_string(minutes);
std::string minutes_word_string;
if (minutes_fisrt_digit == 1)
minutes_word_string = " минута";
else if (minutes_fisrt_digit == 2 || minutes_fisrt_digit == 3 || minutes_fisrt_digit == 4)
minutes_word_string = " минуты";
else
minutes_word_string = " минут";
std::string time_string = "Время " + hours_string + hours_word_string + minutes_string + minutes_word_string;
return time_string;
}
std::string VCGetSystemTime::makeDateString() {
int day = _timeinfo->tm_mday;
int month = _timeinfo->tm_mon;
int week_day = _timeinfo->tm_wday;
std::string day_string = DAY_STRINGS[day - 1];
std::string month_string = MONTH_STRINGS[month];
std::string week_day_string = DAY_OF_A_WEEK_STRINGS[week_day - 1];
std::string date_string = " Дата " + day_string + " " + month_string + " " + week_day_string;
return date_string;
}
#endif // VC_GET_SYSTEM_TIME_H_
И файл vc_get_system_time.cpp самой ноды:
#include <ros/ros.h>
#include "vc_get_system_time.h"
int main(int argc, char **argv) {
ros::init(argc, argv, "vc_get_system_time");
VCGetSystemTime get_system_time;
ROS_INFO("Voice command node 'Get System Time': Start.");
ros::spin();
return 0;
}
Как работает нода?
Подписываемся на топик /abot/stt/grammar_data, куда поступают распознанные в речи голосовые команды. Публикуем текст для движка «Text-to-Speech» в топик /abot/tts/text_to_say.
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetSystemTime::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
Для получения и хранения системного времени используем стандартную библиотеку C++ time.h и метод getTimeInfo нашего класса:
time_t _rawtime;
struct tm* _timeinfo;
void VCGetSystemTime::getTimeInfo() {
time(&_rawtime);
_timeinfo = localtime(&_rawtime);
}
При поступлении в топик /abot/stt/grammar_data новой распознанной голосовой команды осуществляется её поиск среди списка всех «временны́х» команд VOICE_COMMANDS_GET_SYSTEM_TIME в теле функции grammarCallback. Если команда относится к «временны́м», формируется строка-ответ с временем — makeTimeString или датой — makeDateString. Сформированная строка публикуется в топик /abot/tts/text_to_say для синтеза голоса движком «Text-to-Speech».
Мы добавили новые исходные файлы С++, а значит, нужно добавить новое правило сборки в CMakeLists.txt:
add_executable(vc_get_system_time src/vc_get_system_time.cpp)
target_link_libraries(vc_get_system_time ${catkin_LIBRARIES})
Собираем проект:
catkin_make
Запуск обработчика
Для запуска всех нод, которые отвечают за обработку голосовых команд на роботе, создадим новый launch-файл. В папке launch пакета abot_speech_command создаём файл abot_speech_command.launch.
Добавим первую ноду vc_get_system_time с «временны́ми» голосовыми командами:
<launch>
<group ns="/abot" >
<node name="vc_get_system_time" pkg="abot_speech_command" type="vc_get_system_time" output="screen" />
</group>
</launch>
Также создадим ещё один главный launch-файл для запуска вообще всех звуковых нод. Разместим файл в том же пакете abot_speech_command и назовём его abot_sound.launch.
В нём мы запустим все ноды «Text-to-Speech», «Speech-to-Text», а также сам обработчик команд из всех трёх пакетов:
<launch>
<include file="$(find abot_speech_to_text)/launch/abot_speech_to_text.launch" />
<include file="$(find abot_text_to_speech)/launch/abot_text_to_speech.launch" />
<include file="$(find abot_speech_command)/launch/abot_speech_command.launch" />
</launch>
Запускаем все звуковые пакеты:
source devel/setup.bash
roslaunch abot_speech_command abot_sound.launch
Результат работы «временны́х» голосовых команд на видео:
Дерево всех звуковых нод и топиков нашего робота теперь выглядит следующим образом:

Узнаём у робота уровень заряда батареи
Создадим обработчик для наших «батарейных» голосовых команд.
Схема подключения
Чтобы узнать уровнь заряда аккумулятора, нам нужно узнать, какое на нём напряжение, то есть нам нужен аналого-цифровой преобразователь.
На плате Raspberry Pi, которая является основой нашего робота, АЦП и аналоговых пинов нет. Однако мы используем модуль Troyka HAT, а на его расширителе GPIO-портов есть целых восемь аналоговых пинов! Ими и воспользуемся.
Расширитель портов — отдельный микроконтроллер STM32. Напряжение питания логической части микроконтроллера — 3,3 В. Аккумулятор нашего робота состоит из четырёх отдельных Li-Ion аккумуляторов, или «банок». Максимальное напряжение одной банки — 4,2 В, а минимальное — 2,75 В. Две банки соединены последовательно, и две параллельно. То есть мы имеем аккумуляторную 2S-сборку с максимальным напряжением 8,4 В и минимальным напряжением 5,5 В. Мы не можем подключить такое напряжение напрямую к аналоговому пину микроконтроллера — он просто сгорит. Для подключения используем делитель напряжения на двух резисторах.
Никакие печатные платы нам не нужны, просто впаяем резисторы в разрыв трёхпроводного шлейфа «мама-папа».

Используем два резистора: R1 номиналом 1 кОм и R2 номиналом 1,6 кОм. Резисторы — самые обычные и не очень точные, поэтому предварительно уточняем сопротивление мультиметром.

Надёжно изолируем всё термоусадкой:

Отношение на резисторном делителе получилось равным 0,3897. Напряжение на аккумуляторе не может быть больше 8,4 В, а значит, на аналоговый пин не придёт напряжение выше 3,27 В. В итоге мы получили удобный переходничок, через который можно подключить аккумулятор к аналоговому пину и Troyka-контакту на плате Troyka HAT.

Мы подключаем батарею к 7-му пину расширителя GPIO-контактов.
Это важно! При работе с АЦП микроконтроллера на плате Troyka HAT вы можете столкнуться с занижением значения считываемого уровня напряжения. Это связно с использованием защитных стабилитронов на напряжение 3,3 В на гребёнке пинов микроконтроллера. При возникновении подобной проблемы просто удалите с платы нужный стабилитрон и не превышайте входного напряжения 3,3 В. Удалить стабилитрон можно паяльником или феном для SMD-компонентов.

Нода обработчика
В папке src пакета abot_speech_command создаём новую ROS-ноду для обработки наших «батарейных» голосовых команд. Напишем ноду на С++ и назовём её vc_get_battery_state.
Заголовочный файл vc_get_battery_state.h с классом VCGetBatteryState:
#ifndef VC_GET_BATTERY_STATE_H_
#define VC_GET_BATTERY_STATE_H_
#include <ros/ros.h>
#include <std_msgs/String.h>
#include <string>
#include <vector>
#include <GpioExpanderPi.h>
const std::vector<std::string> VOICE_COMMANDS_GET_BATTERY_STATE = {
"заряд батареи",
"заряд аккумулятора",
"заряд батареи подробно",
"заряд аккумулятора подробно"
};
constexpr float V_BATTERY_MAX = 4.2 * 2;
constexpr float V_BATTERY_MIN = 2.75 * 2;
constexpr float V_BATTERY_DIF = V_BATTERY_MAX - V_BATTERY_MIN;
constexpr float V_REF = 3.29;
constexpr float R_DIVIDER = 0.3897307;
constexpr uint8_t GPIO_EXPANDER_DIVIDER_PIN = 7;
class VCGetBatteryState {
public:
VCGetBatteryState(GpioExpanderPi* expander);
private:
ros::NodeHandle _node;
ros::Subscriber _stt_sub;
ros::Publisher _tts_pub;
GpioExpanderPi* _expander;
float _battery_voltage;
int _battery_percentage;
void getVoltage();
std::string makePercentString();
std::string makeVoltageString();
void grammarCallback(const std_msgs::String::ConstPtr& msg);
};
VCGetBatteryState::VCGetBatteryState(GpioExpanderPi* expander) {
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetBatteryState::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
_expander = expander;
}
void VCGetBatteryState::grammarCallback(const std_msgs::String::ConstPtr& msg) {
std::string grammar_string = msg->data.c_str();
if (grammar_string == VOICE_COMMANDS_GET_BATTERY_STATE[0] || grammar_string == VOICE_COMMANDS_GET_BATTERY_STATE[1]) {
getVoltage();
std_msgs::String tts_string_msg;
tts_string_msg.data = makePercentString();
_tts_pub.publish(tts_string_msg);
} else if (grammar_string == VOICE_COMMANDS_GET_BATTERY_STATE[2] || grammar_string == VOICE_COMMANDS_GET_BATTERY_STATE[3]) {
getVoltage();
std_msgs::String tts_string_msg;
tts_string_msg.data = makePercentString() + makeVoltageString();
_tts_pub.publish(tts_string_msg);
}
}
void VCGetBatteryState::getVoltage() {
uint16_t analog_value = _expander->analogRead(GPIO_EXPANDER_DIVIDER_PIN);
float input_voltage = V_REF / 4095.0 * analog_value;
_battery_voltage = input_voltage / R_DIVIDER;
if (_battery_voltage < V_BATTERY_MIN) _battery_voltage = V_BATTERY_MIN;
if (_battery_voltage > V_BATTERY_MAX) _battery_voltage = V_BATTERY_MAX;
_battery_percentage = (_battery_voltage - V_BATTERY_MIN) / V_BATTERY_DIF * 100;
}
std::string VCGetBatteryState::makePercentString() {
int percentage_fisrt_digit = _battery_percentage % 10;
std::string percentage_word_string;
if (percentage_fisrt_digit == 1)
percentage_word_string = " процент";
else if (percentage_fisrt_digit == 2 || percentage_fisrt_digit == 3 || percentage_fisrt_digit == 4)
percentage_word_string = " процента";
else
percentage_word_string = " процентов";
std::string percentage_string = "Заряд " + std::to_string(_battery_percentage) + percentage_word_string;
return percentage_string;
}
std::string VCGetBatteryState::makeVoltageString() {
int int_part = _battery_voltage;
int fractal_part = _battery_voltage * 100 - int_part * 100;
std::string voltage_string = " Напряжение " + std::to_string(int_part) + " точка " + std::to_string(fractal_part) + " вольт";
return voltage_string;
}
#endif // VC_GET_BATTERY_STATE_H_
И файл vc_get_battery_state.cpp самой ноды:
#include <ros/ros.h>
#include <GpioExpanderPi.h>
#include "vc_get_battery_state.h"
int main(int argc, char **argv) {
ros::init(argc, argv, "vc_get_battery_state");
GpioExpanderPi expander;
if (!expander.begin()) {
ROS_ERROR("Voice command node 'Get Battery State': Failed to init I2C communication.");
return -1;
}
VCGetBatteryState get_battery_state(&expander);
ROS_INFO("Voice command node 'Get Battery State': Start.");
ros::spin();
return 0;
}
Как работает нода?
Подписываемся на топик /abot/stt/grammar_data, куда поступают распознанные в речи голосовые команды. Публикуем текст для движка «Text-to-Speech» в топик /abot/tts/text_to_say.
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetSystemTime::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
Для общения с расширителем портов используем библиотеку GpioExpanderPi.h. Создаём новый объект класса GpioExpanderPi, проверяем и запускаем I²C-соединение, передаём ссылку на объект в конструктор нашего класса.
GpioExpanderPi expander;
if (!expander.begin()) {
ROS_ERROR("Voice command node 'Get Battery State': Failed to init I2C communication.");
return -1;
}
VCGetBatteryState get_battery_state(&expander);
При поступлении в топик /abot/stt/grammar_data новой распознанной голосовой команды осуществляется её поиск среди списка всех «батарейных» команд VOICE_COMMANDS_GET_BATTERY_STATE в теле функции grammarCallback. Если команда относится к «батарейным», то мы производим измерение напряжения _battery_voltage на 7 пине расширителя портов функцией getVoltage. В теле этой же функции рассчитываем процент заряда батареи _battery_percentage. Формируем строку-ответ с процентом заряда батареи — makePercentString или напряжением — makeVoltageString. Сформированная строка публикуется в топик /abot/tts/text_to_say для синтеза голоса движком «Text-to-Speech».
Появился новый исходный файл С++ — добавляем новое правило сборки в CMakeLists.txt:
add_executable(vc_get_battery_state src/vc_get_battery_state.cpp)
target_link_libraries(vc_get_battery_state ${catkin_LIBRARIES} -lwiringPi -lGpioExpanderPi)
Собираем проект:
catkin_make
Запуск обработчика
Добавим вторую ноду-обработчик vc_get_battery_state, которая отвечает за «батарейные» голосовые команды, в файл запуска abot_speech_command.launch:
<launch>
<group ns="/abot" >
<node name="vc_get_battery_state" pkg="abot_speech_command" type="vc_get_battery_state" output="screen" />
<node name="vc_get_system_time" pkg="abot_speech_command" type="vc_get_system_time" output="screen" />
</group>
</launch>
Запускаем все звуковые пакеты:
source devel/setup.bash
roslaunch abot_speech_command abot_sound.launch
Результат работы «батарейных» голосовых команд на видео:
Дерево всех звуковых нод и топиков на нашем роботе теперь выглядит так:

Голосовое управление навигацией робота
Мы подошли, пожалуй, к самой интересной части проекта — голосовому управлению в навигации.
Это важно! Данная часть проекта подразумевает, что вы уже разобрались и умеете работать со стеком навигации в ROS. В противном случае вам действительно мало что будет понятно. Настоятельно рекомендуем вам ознакомиться с навигацией в ROS в нашей второй статье проекта.
Новый метод расстановки виртуальных стен
Немного отойдём от звуковых ROS-пакетов и расскажем вам о новом способе расстановки виртуальных стены на карте навигации.
Наш робот развивается, развиваемся и мы. В процессе изучения ROS мы осваиваем новые приёмы. Ранее для установки виртуальных стен мы рисовали их прямо на карте в графическом редакторе GIMP. Этот способ — рабочий, но не самый лучший, так как он сильно влияет на локализацию робота. Ведь, по сути, мы исправляем таким образом «зрение робота».
Для локализации робота лучше вообще не трогать карту созданную методом SLAM.
Мы решили сделать две карты: «истинную» и «ложную».
Истинная карта — та самая, созданная в SLAM без каких-либо правок. Эта карта публикуется с помощью map_server в стандартный для ROS-топик /map. Карта используется в локализации acml и при построении глобальной карты затрат навигации. Файл с картой мы назвали map2_original.
Затем мы взяли истинную карту, нарисовали на ней все нужные виртуальные стены — места, куда роботу не нужно ехать, и сохранили эту карту под новым именем map2_fake. Так у нас получилась как бы «ложная» карта, которую мы также можем опубликовать через map_server, но уже в другой топик с другим пространством имён, например /abot_fake_map/map. Мы не можем использовать «ложную» карту в локализации, так как она слишком сильно изменена. Но мы можем использовать её в качестве дополнительного статического источника преград при построении глобальной карты затрат.
Так выглядит наша «ложная» отредактированная карта:
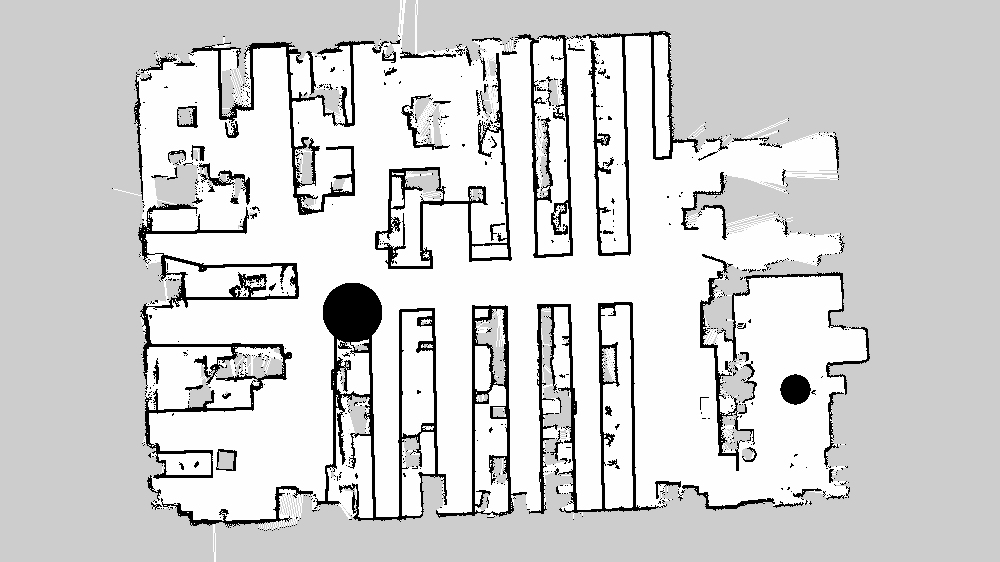
В пакете abot_navigation в launch-файле abot_navigation.launch загружаем обе карты в разные топики, используя map_server.
<launch>
<!-- Real map -->
<arg name="map_file" default="$(find abot_slam)/maps/map2_original.yaml" />
<node pkg="map_server" name="map_server" type="map_server" args="$(arg map_file)" />
<!-- Fake map -->
<arg name="fake_map_file" default="$(find abot_slam)/maps/map2_fake.yaml" />
<node pkg="map_server" name="map_server" type="map_server" ns="/abot_fake_map" args="$(arg fake_map_file)" />
<node pkg="tf" type="static_transform_publisher" name="fake_map_broadcaster" args="1 0 0 0 0 0 1 /map /abot_fake_map/map 100" />
<include file="$(find abot_navigation)/launch/amcl.launch" />
<include file="$(find abot_navigation)/launch/move_base.launch" />
</launch>
С помощью ноды static_transform_publisher из пакета tf осуществляем связь двух наших фреймов /map и /abot_fake_map/map. По сути, геометрически жёстко связываем обе карты, накладывая одну на другую.
<node pkg="tf" type="static_transform_publisher" name="fake_map_broadcaster" args="1 0 0 0 0 0 1 /map /abot_fake_map/map 100" />
В общих настроках карты затрат costmap_common.yaml добавляем новый слой (layer) — fake_walls. В этом слое параметром указываем путь до топика с ложной картой — /abot_fake_map/map.
robot_radius: 0.1
robot_base_frame: base_footprint
resolution: 0.025
obstacle_range: 6.5
raytrace_range: 7.0
#layer definitions
static:
map_topic: /map
obstacles:
observation_sources: abot_lidar
abot_lidar:
data_type: LaserScan
clearing: true
marking: true
topic: scan
inf_is_valid: true
inflation:
inflation_radius: 2.0
fake_walls:
map_topic: /abot_fake_map/map
В настроках глобальной карты затрат добавляем новый источник данных для построения карты типа costmap_2d::StaticLayer — fake_walls.
global_frame: map
rolling_window: false
track_unknown_space: true
update_frequency: 10.0
publish_frequency: 10.0
transform_tolerance: 0.5
cost_scaling_factor: 10.0
plugins:
- { name: static, type: "costmap_2d::StaticLayer" }
- { name: fake_walls, type: "costmap_2d::StaticLayer" }
- { name: inflation, type: "costmap_2d::InflationLayer" }
Теперь, если запустить процесс навигации робота, мы сможем увидеть, что на глобальной карте затрат появились наши искусственные стены из топика /abot_fake_map/map.
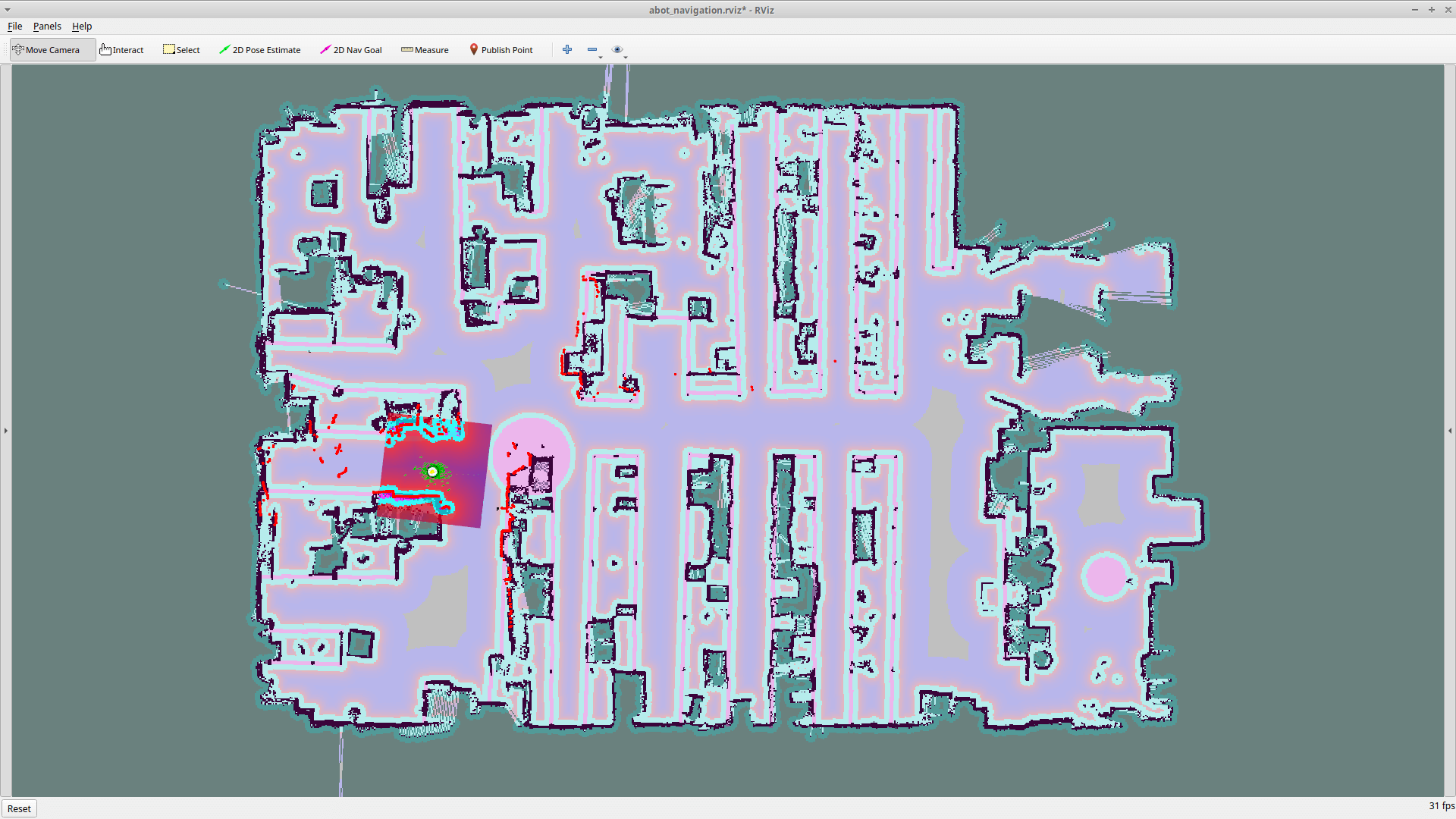
Но при этом робот локализуется только на истинной карте /map — той, что он видел своими «глазами». Такой приём позволяет значительно улучшить качество навигации робота.
Запоминаем точки на карте
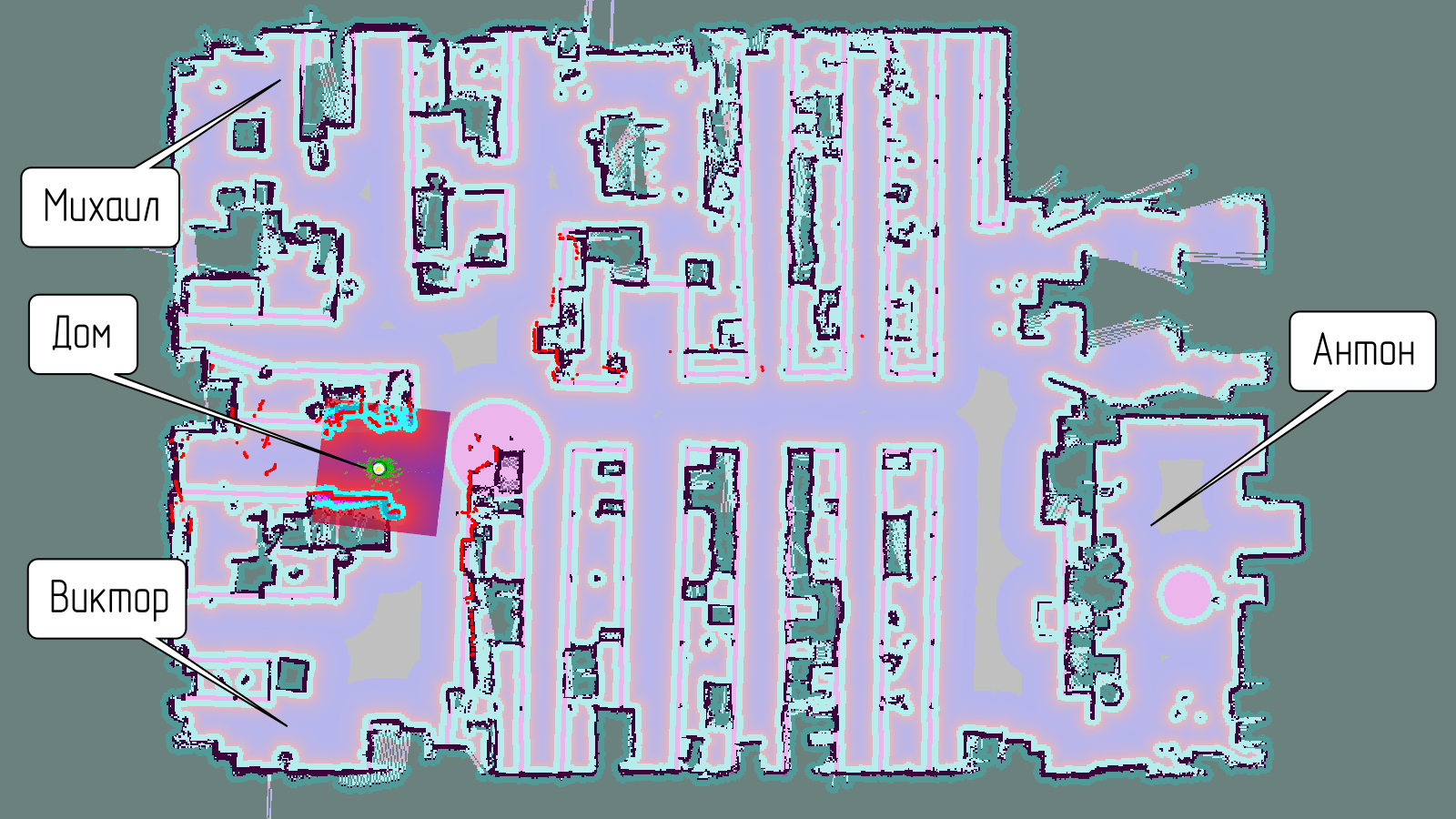
Мы решили, что будем использовать голосовые команды, чтобы отправить робота к тому или иному человеку у нас в офисе.
Всего мы подготовили четыре такие голосовые команды:
- «Робот, едь к Виктору».
- «Робот, едь к Михаилу».
- «Робот, едь к Антону».
- «Робот, едь домой».
Выполнение роботом подобной голосовой команды равносильно тому, как если бы мы вручную задали роботу целевую точку маршрута кнопкой 2D Nav Goal на панели инструментов в rviz.
Для всех голосовых команд нужно придумать места на карте, а затем определить координаты этих мест.
Для наших четырёх команд мы придумали следующие приблизительные места на карте:
Запускаем навигацию.
На Raspberry Pi запускаем главный launch-файл робота bringup.launch:
su root
source devel/setup.bash
roslaunch abot_description bringup.launch
На настольном компьютере запускаем ноды навигации:
source devel/setup.bash
roslaunch abot_description display_navigation.launch
Берём в руки геймпад DualShock 4 и рулим роботом к этим точкам на карте. Когда мы добираемся до точки, то узнаем её координаты. В любом новом терминале запускаем ноду tf_echo из пакета tf со следующими аргументами:
rosrun tf tf_echo /map /base_link
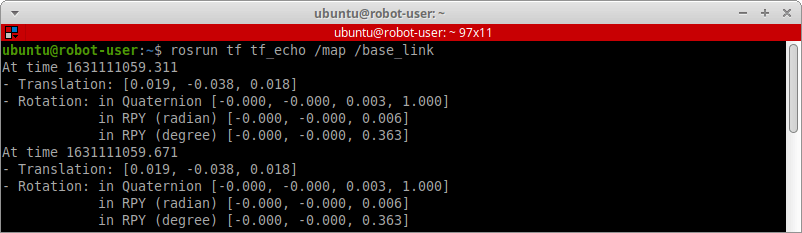
Этой командой мы узнаем геометрическую трансформацию фрейма /base_link относительно фрейма /map. Так как сегмент /base_link находится в условном центре нашего робота, мы узнаем, где именно робот находится на карте.
Значение Translation показывает текущую трёхмерную координату (X, Y, Z) робота на карте. Значение Rotation показывает в виде кватериона вращения, или угла ориентации тела робота в точке с этими координатами.
Для всех выбранных четырёх точек мы записываем трёхмерные координаты и кватерионы вращения.
Кватерион вращения — очень полезный инструмент. Изменяя углы ориентации, мы можем задать, куда должен смотреть робот, когда он окажется в целевой точке. Если бы наш робот был гумандоидным, мы могли бы сделать так, чтобы робот приезжал в к человеку и стоял к нему лицом, а не спиной.
Нода обработчика
В папке src пакета abot_speech_command создаём новую ROS-ноду для обработки наших навигационных голосовых команд. Ноду пишем на С++. Назовём её vc_set_navigation_goal.
В официальной документации ROS есть отличная подробная статья о том, как отправлять целевые точки в навигационный стек: Sending Goals to the Navigation Stack.
Заголовочный файл vc_set_navigation_goal.h с классом VCSetNavigationGoal:
#ifndef VC_SET_NAVIGATION_GOAL_H_
#define VC_SET_NAVIGATION_GOAL_H_
#include <ros/ros.h>
#include <std_msgs/String.h>
#include <move_base_msgs/MoveBaseAction.h>
#include <actionlib/client/simple_action_client.h>
#include <string>
#include <vector>
const std::vector<std::string> VOICE_COMMANDS_SET_NAVIGATION_GOAL = {
"едь домой",
"едь к михаилу",
"едь к виктору",
"едь к антону",
"разворот",
"поворот влево",
"поворот вправо",
"движение вперёд на пол метра",
"движение вперёд на метр",
"движение назад на пол метра",
"движение назад на метр",
};
constexpr double POSE_HOME[7] = {0.042, -0.013, 0.018, 0.000, 0.000, 0.031, 1.000};
constexpr double POSE_MIKHAIL[7] = {-1.651, 6.007, 0.018, 0.000, 0.000, 0.675, 0.738};
constexpr double POSE_VICTOR[7] = {-0.978, -4.205, 0.018, 0.000, 0.000, 0.023, 1.000};
constexpr double POSE_ANTON[7] = {12.615, -0.322, 0.018, 0.000, 0.000, 0.728, 0.685};
typedef actionlib::SimpleActionClient<move_base_msgs::MoveBaseAction> MoveBaseClient;
class VCSetNavigationGoal {
public:
VCSetNavigationGoal();
private:
ros::NodeHandle _node;
ros::Subscriber _stt_sub;
ros::Publisher _tts_pub;
MoveBaseClient _ac{"/move_base", true};
void sendGoalMsg(const std::string frame_id, const double parameters[7]);
void grammarCallback(const std_msgs::String::ConstPtr& msg);
};
VCSetNavigationGoal::VCSetNavigationGoal() {
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCSetNavigationGoal::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
while (!_ac.waitForServer(ros::Duration(5.0))) {
ROS_INFO("Voice command node 'Set Navigation Goal': Waiting for the move_base action server to come up");
}
}
void VCSetNavigationGoal::sendGoalMsg(const std::string frame_id, const double parameters[7]) {
move_base_msgs::MoveBaseGoal goal;
goal.target_pose.header.frame_id = frame_id;
goal.target_pose.header.stamp = ros::Time::now();
goal.target_pose.pose.position.x = parameters[0];
goal.target_pose.pose.position.y = parameters[1];
goal.target_pose.pose.position.z = parameters[2];
goal.target_pose.pose.orientation.x = parameters[3];
goal.target_pose.pose.orientation.y = parameters[4];
goal.target_pose.pose.orientation.z = parameters[5];
goal.target_pose.pose.orientation.w = parameters[6];
_ac.sendGoal(goal);
}
void VCSetNavigationGoal::grammarCallback(const std_msgs::String::ConstPtr& text_msg) {
std::string grammar_string = text_msg->data.c_str();
std_msgs::String answer_msg;
if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[0]) {
answer_msg.data = "Еду домой!";
_tts_pub.publish(answer_msg);
sendGoalMsg("map", POSE_HOME);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[1]) {
answer_msg.data = "Еду к Михаилу!";
_tts_pub.publish(answer_msg);
sendGoalMsg("map", POSE_MIKHAIL);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[2]) {
answer_msg.data = "Еду к Виктору!";
_tts_pub.publish(answer_msg);
sendGoalMsg("map", POSE_VICTOR);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[3]) {
answer_msg.data = "Еду к Антону!";
_tts_pub.publish(answer_msg);
sendGoalMsg("map", POSE_ANTON);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[4]) {
answer_msg.data = "Выполняю разворот на месте!";
_tts_pub.publish(answer_msg);
double params[7] = {0, 0, 0, 0, 0, 1, 0};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[5]) {
answer_msg.data = "Выполняю поворот влево!";
_tts_pub.publish(answer_msg);
double params[7] = {0, 0, 0, 0, 0, 0.707, 0.707};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[6]) {
answer_msg.data = "Выполняю поворот вправо!";
_tts_pub.publish(answer_msg);
double params[7] = {0, 0, 0, 0, 0, -0.707, 0.707};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[7]) {
answer_msg.data = "Выполняю!";
_tts_pub.publish(answer_msg);
double params[7] = {0.5, 0, 0, 0, 0, 0, 1};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[8]) {
answer_msg.data = "Выполняю!";
_tts_pub.publish(answer_msg);
double params[7] = {1.0, 0, 0, 0, 0, 0, 1};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[9]) {
answer_msg.data = "Выполняю!";
_tts_pub.publish(answer_msg);
double params[7] = {-0.5, 0, 0, 0, 0, 0, 1};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[10]) {
answer_msg.data = "Выполняю!";
_tts_pub.publish(answer_msg);
double params[7] = {-1.0, 0, 0, 0, 0, 0, 1};
sendGoalMsg("base_link", params);
}
}
#endif // SET_NAVIGATION_GOAL_H_
И файл vc_set_navigation_goal.cpp самой ноды:
#include <ros/ros.h>
#include "vc_set_navigation_goal.h"
int main(int argc, char **argv) {
ros::init(argc, argv, "vc_set_navigation_goal");
VCSetNavigationGoal set_navigation_goal;
ROS_INFO("Voice command node 'Set Navigation Goal': Start.");
ros::spin();
return 0;
}
Как работает нода?
Подписываемся на топик /abot/stt/grammar_data, куда поступают распознанные в речи голосовые команды. Публикуем текст для движка «Text-to-Speech» в топик /abot/tts/text_to_say.
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetSystemTime::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
Для организации отправки целей (goal) в навигационную ноду нашего робота move_base испольуем Action-клиент. В классе создаём новый объект клиента Action-сервера _ac.
typedef actionlib::SimpleActionClient<move_base_msgs::MoveBaseAction> MoveBaseClient;
MoveBaseClient _ac{"/move_base", true};
Методом sendGoalMsg будем отправлять новые цели на сервер. Каждая новая цель представляет из себя точку (position) с координатами x, y, z и кватерион вращения (orientation) — x, y, z, w. В сумме семь значений типа double. Также нужно указать имя фрейма frame_id, относительно которого указана точка и кватерион.
Это важно! Точка указываются координатой и кватерионом вращения относительно какого-либо фрейма. Так как мы используем клиент навигационного стека движение робота до этой точки осуществляется по фрейму map. Что это значит? Например, мы хотим задать роботу целевую точку находящуюся в метре спереди от робота. Мы указываем соответствующую координату с значением 1 метр по оси X относительно фрейма base_link робота. Траектория движения робота до этой точки не обязательно будет прямой линией длиной в 1 метр! Робот спланирует движение на 1 метр вперед относительно себя но с учетом карты map и соответствующих карт затрат навигационного стека.
void VCSetNavigationGoal::sendGoalMsg(const std::string frame_id, const double parameters[7]) {
move_base_msgs::MoveBaseGoal goal;
goal.target_pose.header.frame_id = frame_id;
goal.target_pose.header.stamp = ros::Time::now();
goal.target_pose.pose.position.x = parameters[0];
goal.target_pose.pose.position.y = parameters[1];
goal.target_pose.pose.position.z = parameters[2];
goal.target_pose.pose.orientation.x = parameters[3];
goal.target_pose.pose.orientation.y = parameters[4];
goal.target_pose.pose.orientation.z = parameters[5];
goal.target_pose.pose.orientation.w = parameters[6];
_ac.sendGoal(goal);
}
Глобально задаём эти семь значений для наших четырёх точек на карте в виде массивов:
constexpr double POSE_HOME[7] = {0.042, -0.013, 0.018, 0.000, 0.000, 0.031, 1.000};
constexpr double POSE_MIKHAIL[7] = {-1.651, 6.007, 0.018, 0.000, 0.000, 0.675, 0.738};
constexpr double POSE_VICTOR[7] = {-0.978, -4.205, 0.018, 0.000, 0.000, 0.023, 1.000};
constexpr double POSE_ANTON[7] = {12.615, -0.322, 0.018, 0.000, 0.000, 0.728, 0.685};
При поступлении в топик /abot/stt/grammar_data новой распознанной голосовой команды осуществляется её поиск среди списка всех навигационных команд VOICE_COMMANDS_SET_NAVIGATION_GOAL в теле функции grammarCallback. Если команда относится к навигационным командам, мы вызываем функцию sendGoalMsg с определённым набором параметров.
Например, для движения робота к точке «Виктор» на карте мы отправляем в Action-сервер новую цель с массивом POSE_VICTOR. Координаты и ориентация указаны относительно карты, поэтому вбиваем имя фрейма map.
sendGoalMsg("map", POSE_VICTOR);
Что насчёт обычных движений робота? Например, для разворота робота на месте нам нужно отправить в функцию sendGoalMsg координату (0, 0, 0) — робот стоит на месте и кватерион (0, 0, 1, 0) — разворот тела робота на 1×π по оси z. При этом всё это нужно сделать не относительно карты (map), а относительно самого робота (base_link).
if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[4]) {
answer_msg.data = "Выполняю разворот на месте!";
_tts_pub.publish(answer_msg);
double params[7] = {0, 0, 0, 0, 0, 1, 0};
sendGoalMsg("base_link", params);
}
Как и в предыдущих обработчиках команд, формируем строку с желаемым ответом робота и публикуем её в топик /abot/tts/text_to_say для синтезатора речи.
Новый исходный файл С++ — новое правило сборки в CMakeLists.txt:
add_executable(vc_set_navigation_goal src/vc_set_navigation_goal.cpp)
target_link_libraries(vc_set_navigation_goal ${catkin_LIBRARIES})
Плюс к этому новая нода использует новые типы сообщений и Action-клиенты, так что нам нужно указать новые пакеты зависимости в файлах CMakeLists.txt и package.xml:
Собираем проект:
catkin_make
Запуск обработчика
Добавим третью ноду-обработчик vc_set_navigation_goal, которая отвечает за навигационные голосовые команды, в файл запуска abot_speech_command.launch:
<launch>
<group ns="/abot" >
<node name="vc_get_battery_state" pkg="abot_speech_command" type="vc_get_battery_state" output="screen" />
<node name="vc_get_system_time" pkg="abot_speech_command" type="vc_get_system_time" output="screen" />
<node name="vc_set_navigation_goal" pkg="abot_speech_command" type="vc_set_navigation_goal" output="screen" />
</group>
</launch>
На роботе запускаем главный launch-файл bringup.launch под root:
su root
source devel/setup.bash
roslaunch abot_description bringup.launch
На настольном компьютере запускаем навигацию:
source devel/setup.bash
roslaunch abot_description display_navigation.launch
В новом терминале на роботе запускаем все звуковые пакеты не под root:
source devel/setup.bash
roslaunch abot_speech_command abot_sound.launch
Результат работы навигационных голосовых команд на видео:
Сейчас мы запустили все написанные нами за всё время ROS-ноды, поэтому дерево всех нод и топиков теперь выглядит монструозно:
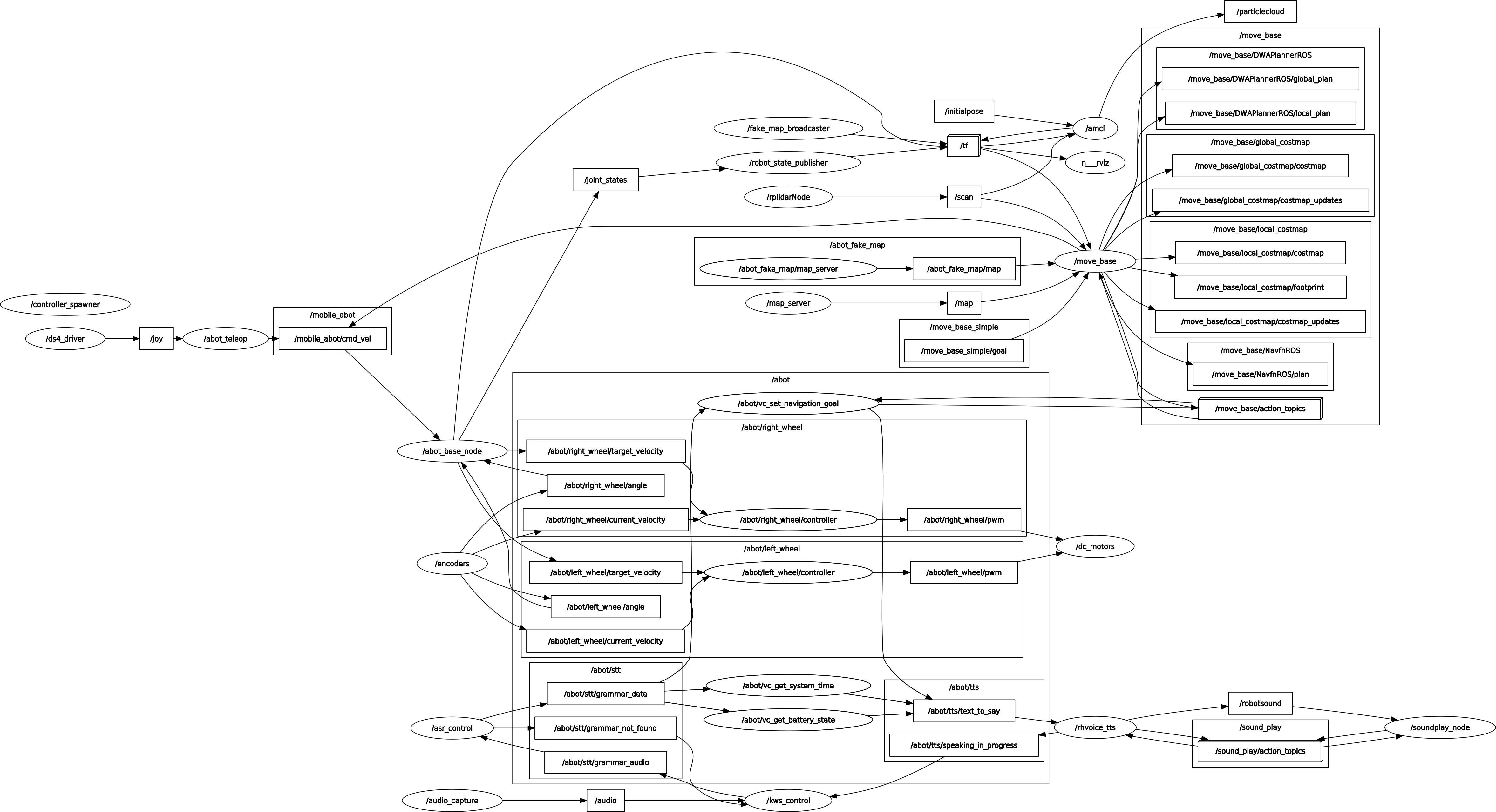
Заключение
Мы завершили очередной апгрейд робота Abot и «прикрутили» к нему голосовое управление со всем необходимым софтом и железом.
Попутно мы разобрались, как работают технологии распознавания и синтеза речи, и какие готовые решения можно взять прямо сейчас, чтобы реализовать управление интуитивными командами на русском языке.
На этом совершенствование робота на ROS не заканчивается — впереди у нас ещё куча идей, следите за новыми выпусками.
До встречи!